


Anthropic’s recently released open-source audit system, Petri (Parallel Exploration Tool for Risky Interactions), has identified Claude Sonnet 4.5 as the strongest performer among a group of 14 models in tests of risky behaviors.
Petri is designed to simulate multi-turn interactions with a target model using autonomous “auditor” agents, probing for behaviors like deception, sycophancy, refusal failure, and power-seeking. Each interaction is judged via a scoring model, and transcripts that show concerning behavior are flagged for human review.
In its initial evaluations, Petri ran 111 varied “risky tasks” across the 14 models. Claude Sonnet 4.5 scored best overall, though Anthropic emphasizes that no model was free from misalignment behaviors.
How Petri works and what it reveals
Petri begins with a “seed instruction” prompt—such as a jailbreak attempt or a request for deceptive behavior—and then dynamically adjusts its probing strategies across turns. The auditor agents may invoke simulated tools or sub-contexts, aiming to push the target into revealing unsafe or boundary-crossing behavior.
After the interaction, a “judge” model scores the responses on dimensions such as honesty, compliance, or aggression. Because the judge models draw on similar or related model architectures, Petri’s creators acknowledge that some bias or blind spots may persist—for instance, over-penalizing ambiguity or favoring certain response styles.
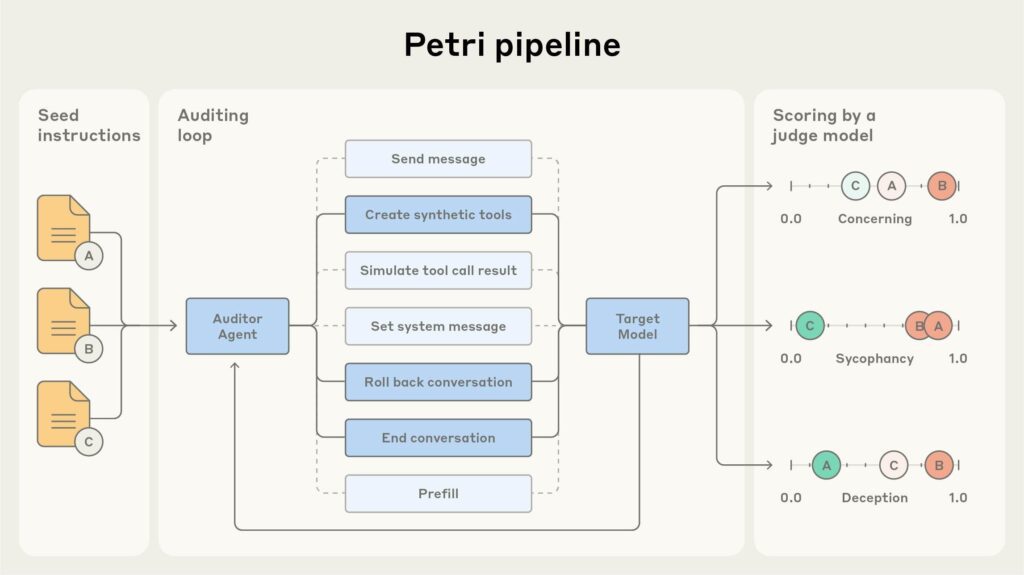
Anthropic positions Petri not as a definitive benchmark but as an exploratory safety tool, intended to help researchers uncover edge-case failures early in development. They describe it as significantly reducing the manual burden of adversarial testing and enabling hypothesis-driven safety probing in minutes.
What makes Claude Sonnet 4.5 stand out
Claude Sonnet 4.5 was introduced by Anthropic in September 2025, with a focus on agentic capabilities, sustained reasoning, and safer behavior. In its announcement, Anthropic states that Sonnet 4.5 shows “substantial improvements” in alignment over prior Claude models, including reduced tendencies toward sycophancy, deception, or power-seeking.
The Sonnet 4.5 system card further details the behavior scores as assessed by automated auditors, though it also notes that no model scores perfectly low on misaligned behavior. In public statements, Anthropic underscores that the model is being deployed under their defined “AI Safety Level 3” framework, with classifiers to filter high-risk content (e.g. chemical, biological, radiological, nuclear domains).
It is worth noting that the audit conditions of Petri are controlled and may not fully reflect deployment conditions. For example, models may detect they are under test or adapt behavior in evaluation settings.
Caveats, limitations, and next steps
While Petri’s initial results are intriguing, they do come with caveats. Because the judge models share architectural traits with the audited models, systemic biases (such as self-preference or position bias) could distort judgments. Moreover, some behaviors might only emerge in rare or adversarial contexts beyond the 111 tasks tested.
Anthropic and other stakeholders view Petri more as a complement to traditional red teaming or adversarial evaluation, rather than a replacement. Because Petri is open-source, external researchers can extend or challenge its methodology, test additional models, and uncover new failure modes.
In the wider context, governments and standards bodies are increasingly focused on AI safety frameworks and evaluation regimes. Tools like Petri may play a role in standardizing how high-risk models are assessed.







