


Modern apps ship faster when the database “just works.” That trade-off—time vs. control—is exactly what you navigate when choosing between DigitalOcean’s Managed Databases and running PostgreSQL/MySQL/Redis yourself on Droplets. This guide explains what you gain, what you give up, how costs behave, and how to implement both paths cleanly. You will need a DigitalOcean account to follow along; the examples use doctl, psql, mysql, and redis-cli so you can get hands-on quickly.
What “managed” actually covers
Managed Databases on DigitalOcean run on dedicated clusters with platform automation layered on top. DigitalOcean provisions the nodes, applies security patches, executes version upgrades during maintenance windows, backs up data on a rolling basis, and offers optional standby nodes for high availability with automatic failover. With at least one standby node, the service carries a 99.95% monthly uptime SLA; without a standby, the SLA is 99.5%.
Operationally, you also get connection enforcement (TLS by default), point-in-time recovery within the backup window, and push-button vertical and horizontal scaling: you can resize nodes and add read-only replicas to offload reads or place replicas in another region for disaster recovery. You can even promote a read-only node to become a new primary cluster, which is handy for blue/green cutovers or regional moves.
There are limits and design choices to be aware of. Managed clusters use allowlists (“trusted sources”) rather than Cloud Firewalls, and certain engines have product-specific constraints (for example, Managed MongoDB does not support read-only nodes). These constraints rarely block common app patterns, but they shape advanced designs and access models.
Implication: if you value predictable ops with strong guardrails and a clear uptime posture, “managed” buys you time and reduces blast radius. The cost is less low-level control and some feature boundaries per engine; plan around those early.
What “self-managed” entails on Droplets
Running your own database on Droplets gives you full control over versions, extensions, OS tuning, and network security. You decide how to do backups (filesystem snapshots vs. logical dumps vs. WAL archiving), how to fail over, and how to patch. You also carry on-call responsibility for everything above the hypervisor. Droplet pricing is simple and includes pooled egress allowances across your team; you size compute and storage exactly to your needs.
Because you own the stack, you can attach Block Storage, layer in your preferred backup tooling, and choose your RTO/RPO strategy. Spaces, DigitalOcean’s S3-compatible object storage, works with standard S3 tooling for offsite backups. That makes it straightforward to keep durable copies of pg_dump or MySQL dumps, or to archive PostgreSQL WAL using S3-compatible clients.
Implication: if you need bespoke tuning, unusual extensions, or cost-optimized barebones instances, Droplets are flexible. The trade-off is operational toil: you must design, practice, and monitor backups, upgrades, failover, and security changes yourself.
Cost shape: how to compare fairly
Managed Database clusters start at entry-level sizes suitable for development or light production and scale to multi-node setups. The headline “starts at” figure is attractive for small apps, but the meaningful comparison is at equivalent resilience. Adding a standby node for HA (the common production posture) increases managed cost but brings the higher 99.95% SLA and automated failover. On Droplets, matching that resilience means running at least two VMs, configuring replication, setting up a virtual IP or proxy for failover, and paying with your time (and risk) instead of a managed premium.
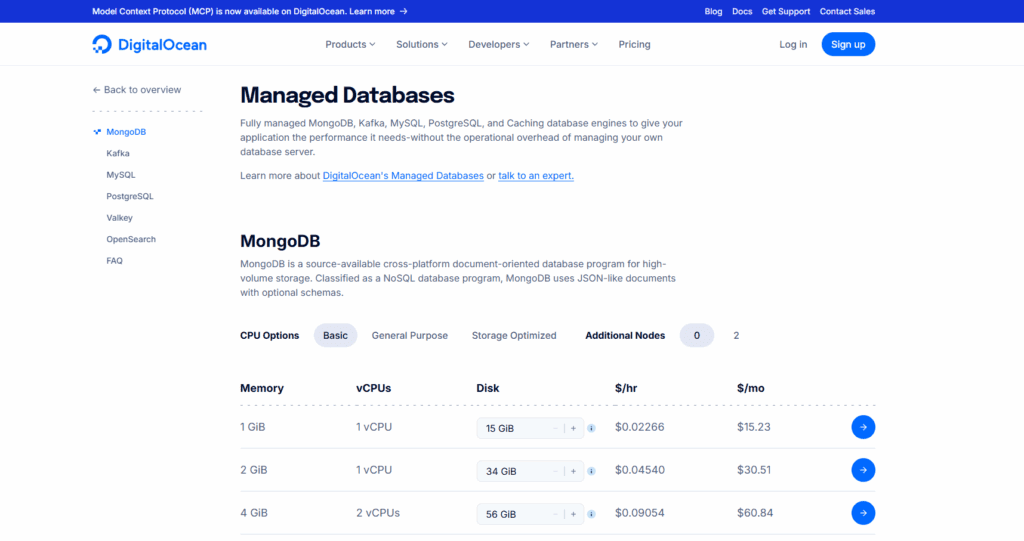
Droplet costs depend on vCPU/RAM/SSD and pooled outbound transfer; additional egress beyond the allowance is billed per GiB. For bursty or read-heavy workloads, you may add a load balancer, cache, or replicas—each with its own cost line. The managed path moves several of those lines under one product, but it charges for the convenience. When you model total cost of ownership, account for on-call coverage and incident time; those human hours are real, even if not on your cloud bill.
Implication: for most teams, managed wins on true production cost at small to mid scale because it reduces failure work; self-managed tends to win when you have atypical needs or can amortize ops across many databases.
Security and access
Managed clusters enforce TLS, rotate certificates, and provide connection strings with least-privilege users you create. Access is controlled via trusted sources (IP allowlists) at the service edge. On Droplets, you can add Cloud Firewalls at the network layer, restrict SSH, and run your own TLS termination or client certs; you carry the patching and hardening. On either path, keep secrets in environment variables or a secret manager and prefer private networking wherever possible.
Implication: managed centralizes security controls but limits network primitives; self-managed gives you full firewall control at the cost of maintenance.
When to choose which: a simple rubric
Choose Managed Databases when you need production reliability quickly, want HA and automated backups out of the box, or plan to scale reads with replicas or span regions without building your own replication and promotion tooling. Choose self-managed on Droplets when you require exotic extensions, kernel-level tuning, unusual replication topologies, or when minimizing cloud spend outranks minimizing operational risk. The moment your app becomes mission-critical, revisit: SLAs and automated failover are often worth the premium.
Hands-on: provisioning a Managed Database
First, install and authenticate the DigitalOcean CLI (doctl). Then create a cluster. The following creates a single-node PostgreSQL cluster; add --num-nodes 2 for a primary+standby HA setup and the higher SLA.
# Authenticate once (stores a local token)
doctl auth init
# Create a PostgreSQL managed database (adjust size/region/engine/version)
doctl databases create example-db \
--engine pg \
--version 16 \
--region nyc1 \
--size db-s-1vcpu-1gb \
--num-nodes 1You can then create a logical database and a user:
# List clusters and grab the cluster ID
doctl databases list
# Create a database inside the cluster
doctl databases db create <cluster-id> appdb
# Create an application user (password is generated)
doctl databases user create <cluster-id> appuserFetch connection details and connect with psql:
# Show connection info including URI and CA cert
doctl databases connection <cluster-id>
# Example psql connection (paste your URI; TLS is on by default)
psql "postgresql://appuser:SECRET@HOST:PORT/appdb?sslmode=require"The process is essentially the same for MySQL and Redis engines. You create the cluster, create a database/user where applicable, and use the provided connection string in your app.
Adding a read-only node and promoting it
If you anticipate read pressure or want a warm regional copy, add a read-only node. You can later promote it to a standalone primary for cutovers or DR tests.
# Add a read-only node
doctl databases replicas create <cluster-id> \
--name readnyc1 \
--region nyc1
# (When needed) promote the replica to its own primary cluster
doctl databases replicas promote <replica-id>This promotion creates an independent cluster based on the replica’s data at the moment of promotion. It will not continue syncing with the original.
Hands-on: standing up a self-managed PostgreSQL on Droplets
You can install directly on Ubuntu, but using containers simplifies upgrades and rollbacks. The example below runs PostgreSQL and ships logical backups to Spaces using the S3-compatible API.
# docker-compose.yaml
services:
postgres:
image: postgres:16
restart: unless-stopped
environment:
POSTGRES_DB: appdb
POSTGRES_USER: appuser
POSTGRES_PASSWORD: change-me
volumes:
- pgdata:/var/lib/postgresql/data
ports:
- "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U appuser -d appdb"]
interval: 10s
timeout: 5s
retries: 5
backup:
image: ghcr.io/kanisterio/kanister-tools:latest
depends_on: [postgres]
entrypoint: ["/bin/sh","-c"]
command: |
while true; do
PGPASSWORD=change-me pg_dump -h postgres -U appuser -d appdb \
| aws s3 cp - s3://your-space-name/pg/`date -u +%Y%m%dT%H%M%SZ`.sql --endpoint-url https://nyc3.digitaloceanspaces.com
sleep 3600
done
environment:
AWS_ACCESS_KEY_ID: your_spaces_key
AWS_SECRET_ACCESS_KEY: your_spaces_secret
volumes:
pgdata: {}Create the Droplet with Docker (Marketplace image), apply a Cloud Firewall to allow only your app hosts on port 5432, and point the backup container to your Spaces bucket. Spaces is fully S3-compatible, so the standard AWS CLI works with an endpoint URL. For production, replace logical dumps with continuous archiving (e.g., wal-g) and test restores regularly.
Connecting from your app
Use the standard drivers and TLS settings you would anywhere else. For MySQL:
mysql --host=HOST --port=25060 -u appuser -p --ssl-mode=REQUIRED appdbFor Redis (managed or self-managed), always prefer TLS and authentication:
redis-cli -u "rediss://:PASSWORD@HOST:PORT/0" PING(Managed Redis defaults and configuration options differ from self-managed Redis; check engine-level limits and plan connection pooling accordingly.)
Backups, recovery, and DR
Managed clusters keep rolling automated backups and support point-in-time recovery within that window. Adding a read-only node in another region gives you low-RPO replication with a simple promotion story for regional incidents. On Droplets, you must design the schedule and destinations: combine filesystem snapshots for fast node recovery with off-Droplet backups in Spaces, and document restore runbooks. Test them. The difference is not only tooling; it is who wakes up at 03:00 when a restore fails.
Bridge: now that you have both paths in hand, use the checklist below to make a decision you will not have to revisit under duress.
Decision checklist
- Availability target: if you need automatic failover with an SLA, choose managed with a standby node; if you can tolerate manual failover and longer downtime, self-managed may be acceptable.
- Operational capacity: if your team cannot comfortably handle backups, upgrades, failover drills, and on-call for the database, managed reduces risk meaningfully.
- Feature needs: if you rely on niche extensions or nonstandard configuration, Droplets give you headroom; if you want replicas and easy region moves, managed simplifies that workflow. Check per-engine limits early.
- Cost reality: compare equivalent resilience, not just instance sizes; include the cost of your time. Factor pooled bandwidth on Droplets and the simplicity premium of managed services.
TL;DR
Start with DigitalOcean Managed Databases if you want production-grade uptime, backups, and scaling without babysitting the server. Drop to self-managed on Droplets when you need total control or extreme cost tuning and are prepared to own the operational lifecycle. Either way, keep connections private and encrypted, back up to Spaces or an external store, and exercise your restores before you need them.
Appendix: quick reference commands
Provision a managed database:
doctl databases create example-db --engine pg --version 16 --region nyc1 --size db-s-1vcpu-1gb --num-nodes 2
doctl databases db create <cluster-id> appdb
doctl databases user create <cluster-id> appuser
doctl databases connection <cluster-id>Connect to PostgreSQL, MySQL, and Redis:
psql "postgresql://appuser:SECRET@HOST:PORT/appdb?sslmode=require"
mysql --host=HOST --port=PORT -u appuser -p --ssl-mode=REQUIRED appdb
redis-cli -u "rediss://:PASSWORD@HOST:PORT/0" INFO serverShip backups to Spaces (S3-compatible):
# Example: pipe a pg_dump to Spaces via AWS CLI with a Spaces endpoint
PGPASSWORD=SECRET pg_dump -h HOST -U appuser -d appdb \
| aws s3 cp - s3://your-space/pg/$(date -u +%Y%m%dT%H%M%SZ).sql \
--endpoint-url https://nyc3.digitaloceanspaces.comThese commands mirror the workflows discussed earlier: create, connect, scale, and protect your data with the operational posture that best fits your team and application.







