Geospatial data is now woven into nearly every modern application, from navigation and logistics to urban planning and climate modeling. Yet most analytical databases treat location as an optional add-on, bolted in through extensions or external libraries. The Apache Sedona community has long pushed against that model, offering distributed engines that integrate spatial analysis into Spark and Flink. In September 2025, the project took a decisive step further: the release of SedonaDB, a single-node analytical database engine designed from the ground up with geospatial as a first-class citizen.
The original Apache Sedona framework solved the challenge of scale. By plugging into Spark or Flink, Sedona enabled massive parallel processing of vector and raster data, complete with spatial joins, clustering, and map algebra. This made sense for organizations handling terabytes of satellite imagery or nationwide transportation data.
But not every use case needs a cluster. Analysts often work on laptops or cloud instances, exploring city-scale datasets, testing workflows, or developing pipelines before deploying them. For them, the overhead of a Spark or Flink cluster is unnecessary. SedonaDB emerges here: a compact, high-performance engine that brings Sedona’s spatial intelligence into a single-node package.
Architecture and Design Choices
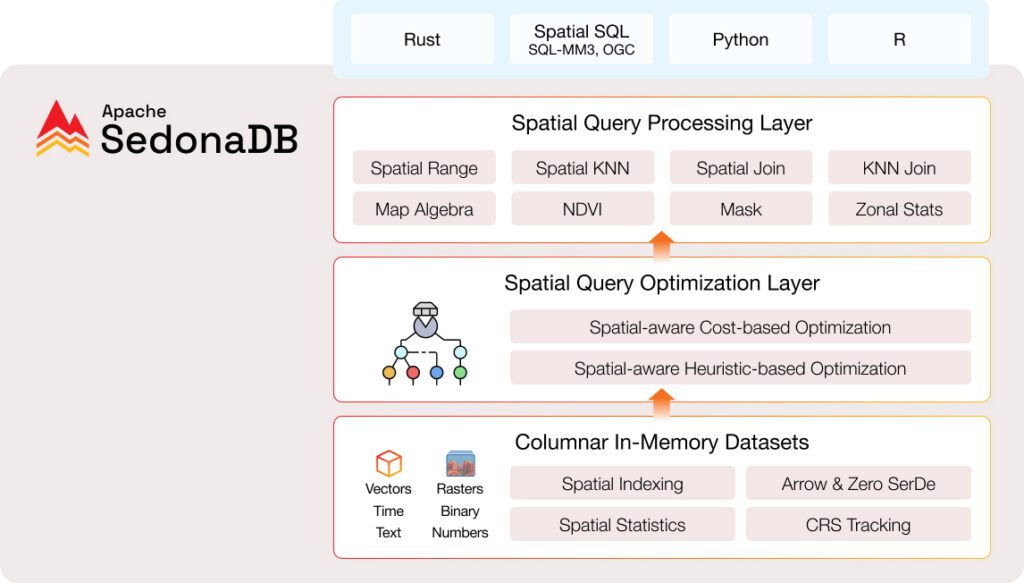
SedonaDB is written in Rust, a language prized for memory safety and performance. Its core relies on columnar in-memory storage and the Apache Arrow format, eliminating serialization overhead when exchanging data with compatible libraries. At query time, SedonaDB applies both heuristic and cost-based spatial optimizations, ensuring that joins and range searches execute with minimal overhead.
Key architectural features include:
- Spatial indexing and statistics: Essential for fast joins, nearest-neighbor, and range queries.
- CRS propagation: Coordinate Reference System metadata flows with data through every transformation.
- Vector and raster support: Vector functions (joins, buffers, KNN queries) are fully available, while raster support is in active development, aiming to match SedonaSpark’s map algebra and NDVI functions [13†source].
- Flexible APIs: Queries can be written in either SQL or Python, and an R API is emerging.
These decisions reflect an ambition not just to add geospatial support but to normalize it into the analytical core.
Performance in Context
The Sedona team benchmarked SedonaDB against DuckDB and GeoPandas using the SpatialBench suite. On both small (scale factor 1) and moderate (scale factor 10) datasets, SedonaDB demonstrated faster performance, particularly in spatial joins and KNN operations.
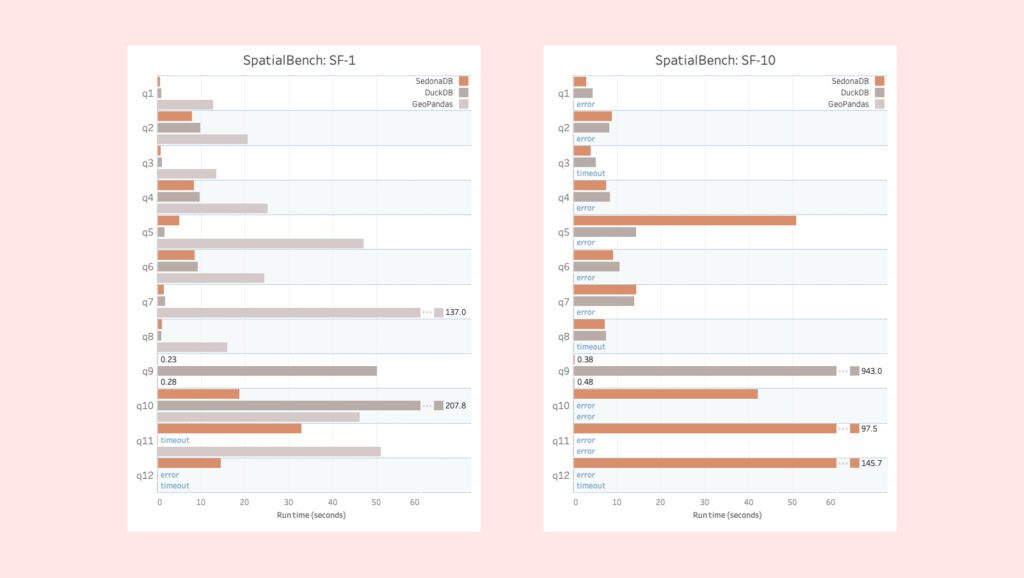
This positioning matters. DuckDB has gained attention as an “in-process OLAP database,” with extensions such as duckdb-spatial adding geospatial support. PostGIS, meanwhile, remains the de facto standard for relational geospatial databases atop PostgreSQL. SedonaDB differentiates itself by building geospatial into its foundation, rather than layering it on.
Where PostGIS excels in transactional support and standards compliance, SedonaDB emphasizes analytical speed, modern file compatibility (GeoParquet, Shapefiles, GeoJSON), and interoperability with Arrow-based tools like GeoPandas and Polars. Against DuckDB, SedonaDB’s advantage is a deeper, more consistent spatial function set, designed with CRS-awareness and raster capability from the start.
Practical Example
A simple workflow shows SedonaDB’s strengths:
import sedona.db as sdb
db = sdb.connect()
# Load a GeoParquet dataset
db.sql("""
CREATE TABLE buildings AS
SELECT * FROM read_parquet('nyc_buildings.parquet')
""")
# Spatial join: buildings intersecting major roads
result = db.sql("""
SELECT b.id, COUNT(*) AS road_hits
FROM buildings b, read_parquet('nyc_roads.parquet') r
WHERE ST_Intersects(b.geom, r.geom)
GROUP BY b.id
""").fetch_all()
print(result[:10])In this example, spatial operators (ST_Intersects) are used as naturally as numeric functions. The workflow runs natively on columnar data, without needing external indexing structures or conversions.
Strengths and Limitations
SedonaDB’s main strengths are:
- Geospatial-native design across SQL and Python.
- Strong performance on analytical workloads.
- Support for both legacy and modern spatial formats.
- Smooth interoperability with Arrow-based libraries.
Current limitations include:
- Single-node scope: not designed for very large-scale or distributed workloads.
- Early-stage raster support: advanced map algebra is still on the roadmap.
- Ecosystem maturity: smaller user and developer base compared to PostGIS or DuckDB.
Implications and Future Directions
SedonaDB expands the spectrum of geospatial computing. At one end, PostGIS provides a battle-tested option for relational geodatabases and transactional applications. At the other, Sedona’s Spark and Flink modules handle massive distributed workloads. SedonaDB sits between these extremes: a fast, lightweight, and geospatially rich engine for interactive analytics and prototyping.
Its design hints at broader trends: analytical systems are converging toward domain-native engines, where geospatial, time-series, or graph operations are not bolted on but designed in. As SedonaDB matures—particularly with raster functions and larger community adoption—it could become the go-to engine for medium-scale geospatial analytics, much as DuckDB has become for tabular OLAP tasks.
For developers, analysts, and researchers navigating a spatially rich world, this new engine offers both practical efficiency and a glimpse of the future of database design.