


Ollama started as a fast way to run open models locally. In 2025 it shifted from a model runner to a research-capable platform by shipping a new engine, multimodal support, and now a first-party Web Search and Web Fetch API. The move matters: you can let an LLM retrieve live sources, ground its reasoning, and keep your stack local or hybrid. First, a brief timeline to orient you: on May 15, 2025 Ollama’s new engine added multimodal support for vision models such as Llama 4, Gemma 3, Qwen 2.5 VL, and Mistral Small; on September 23, 2025 the engine gained precise memory-based model scheduling for better throughput and stability; on September 24, 2025 Ollama introduced Web Search and Web Fetch with a free tier and higher limits in cloud. Together these changes reposition Ollama as an LLM runtime that can search, fetch, and reason over current data with open models you already use.
What you get
You get two primitives.
Web Search takes a natural-language query and returns structured results with title, url, and short content snippets. It is exposed as a REST endpoint and in official Python and JavaScript libraries. Web Fetch takes a specific URL and returns normalized page text and discovered links. Both are designed for tool-use workflows where the model decides when to search, which links to fetch, and how to cite.
Architecture at a glance
flowchart LR
A(User prompt) --> B(Model)
B -- tool call: search --> C[[Web Search API]]
C -->|results| B
B -- tool call: fetch URL --> D[[Web Fetch API]]
D -->|content| B
B --> E{Grounded answer}
subgraph Runtime
B
end
subgraph Network
C
D
end
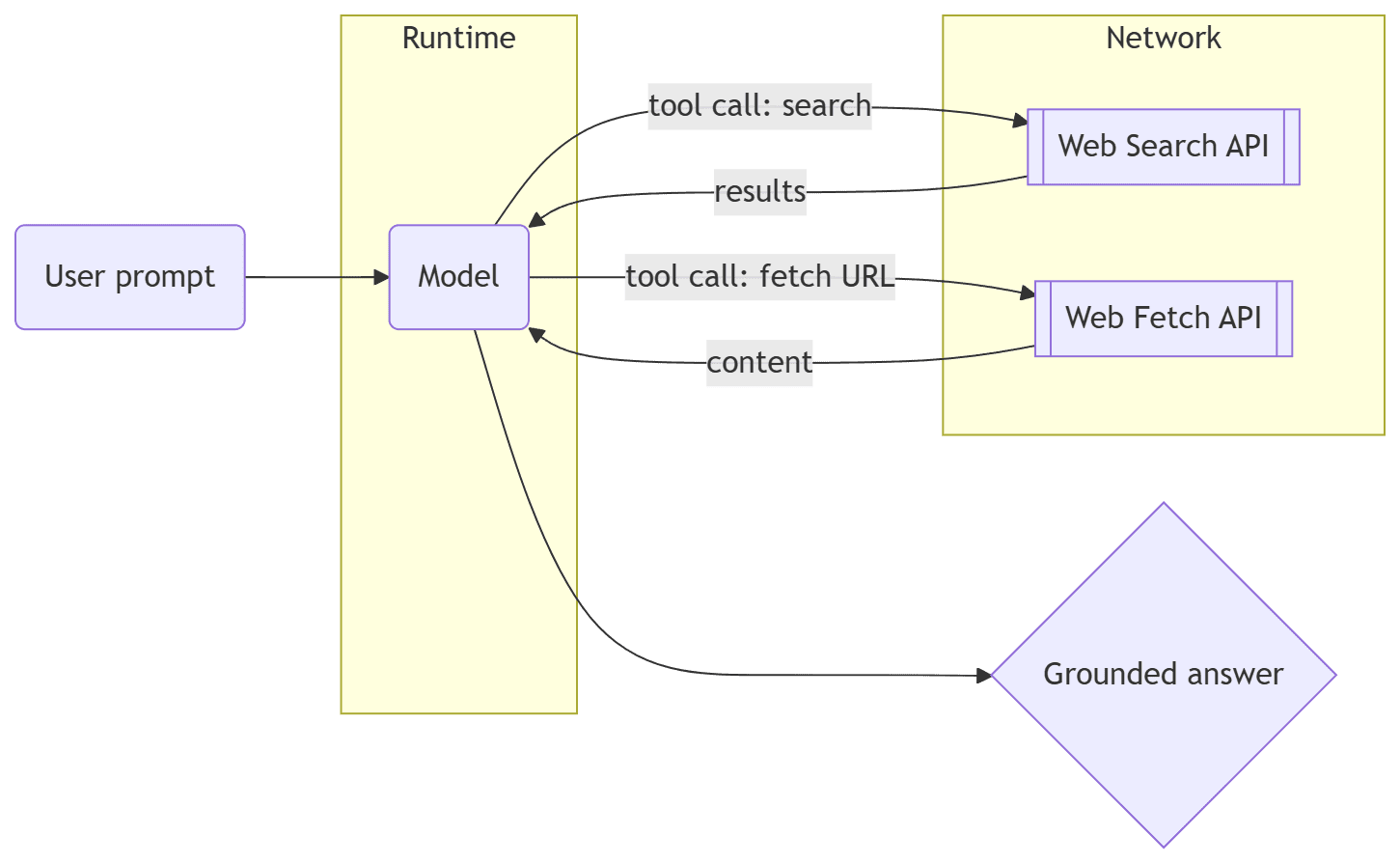
The model runs inside Ollama’s engine. When it needs context, it calls the search tool. It then fetches one or more URLs, summarizes, and writes a grounded answer with references. Engine updates from September 2025 improve stability on multi-GPU systems and reduce OOMs when juggling large contexts for tool output.
Quick start
Assumptions: You have an Ollama account, created an API key, and installed either the Python or JavaScript library.
Create an API key in your account, export it, and make a test call.
export OLLAMA_API_KEY="your_api_key"
curl https://ollama.com/api/web_search \
--header "Authorization: Bearer $OLLAMA_API_KEY" \
-d '{
"query": "what is ollama?"
}'Expected shape:
{
"results": [
{ "title": "Ollama", "url": "https://ollama.com/", "content": "Cloud models are now available..." }
]
}Use Web Fetch when you already know the URL.
curl --request POST https://ollama.com/api/web_fetch \
--header "Authorization: Bearer $OLLAMA_API_KEY" \
--header "Content-Type: application/json" \
--data '{ "url": "https://ollama.com" }'You should get a title, content (normalized text), and links.
Python integration
Install the library and run a query. The return type is a simple dict with a results list.
pip install "ollama>=0.6.0"import ollama
resp = ollama.web_search("What is Ollama?")
for r in resp["results"]:
print(r["title"], r["url"])Fetch a URL when the user supplies one:
from ollama import web_fetch
page = web_fetch("https://ollama.com")
print(page["title"])
print(page["links"][:3])For tool-use inside a chat loop, expose both tools and let the model choose:
from ollama import chat, web_search, web_fetch
tools = [web_search, web_fetch]
messages = [{"role": "user", "content": "Summarize what changed in Ollama’s engine this week with links."}]
while True:
res = chat(model="qwen3:4b", messages=messages, tools=tools, think=True)
if res.message.content:
print(res.message.content)
messages.append(res.message)
if not res.message.tool_calls:
break
for call in res.message.tool_calls:
fn = web_search if call.function.name == "web_search" else web_fetch
result = fn(**call.function.arguments)
messages.append({"role": "tool", "tool_name": call.function.name, "content": str(result)})This pattern mirrors the official “mini search agent” example and works well with small models when you keep results concise.
JavaScript integration
Install and use the official JS client.
npm install "ollama@>=0.6.0"import { Ollama } from "ollama";
const client = new Ollama({ apiKey: process.env.OLLAMA_API_KEY });
const search = await client.webSearch({ query: "what is ollama?" });
console.log(search.results.map(r => r.url));
const fetched = await client.webFetch({ url: "https://ollama.com" });
console.log(fetched.title, fetched.links.slice(0, 3));Tool names and shapes align with the REST API and are documented in the JS repo.
Agent loop design
When you wire these tools into a chat model, keep the loop deterministic and cheap.
sequenceDiagram
participant U as User
participant M as Model
participant S as web_search
participant F as web_fetch
U->>M: "Compare engine updates and show sources."
M->>S: query="Ollama new engine updates"
S-->>M: results[...]
M->>F: url=top_result.url
F-->>M: {title, content, links}
M->>M: synthesize, draft citations
M-->>U: grounded answer + links
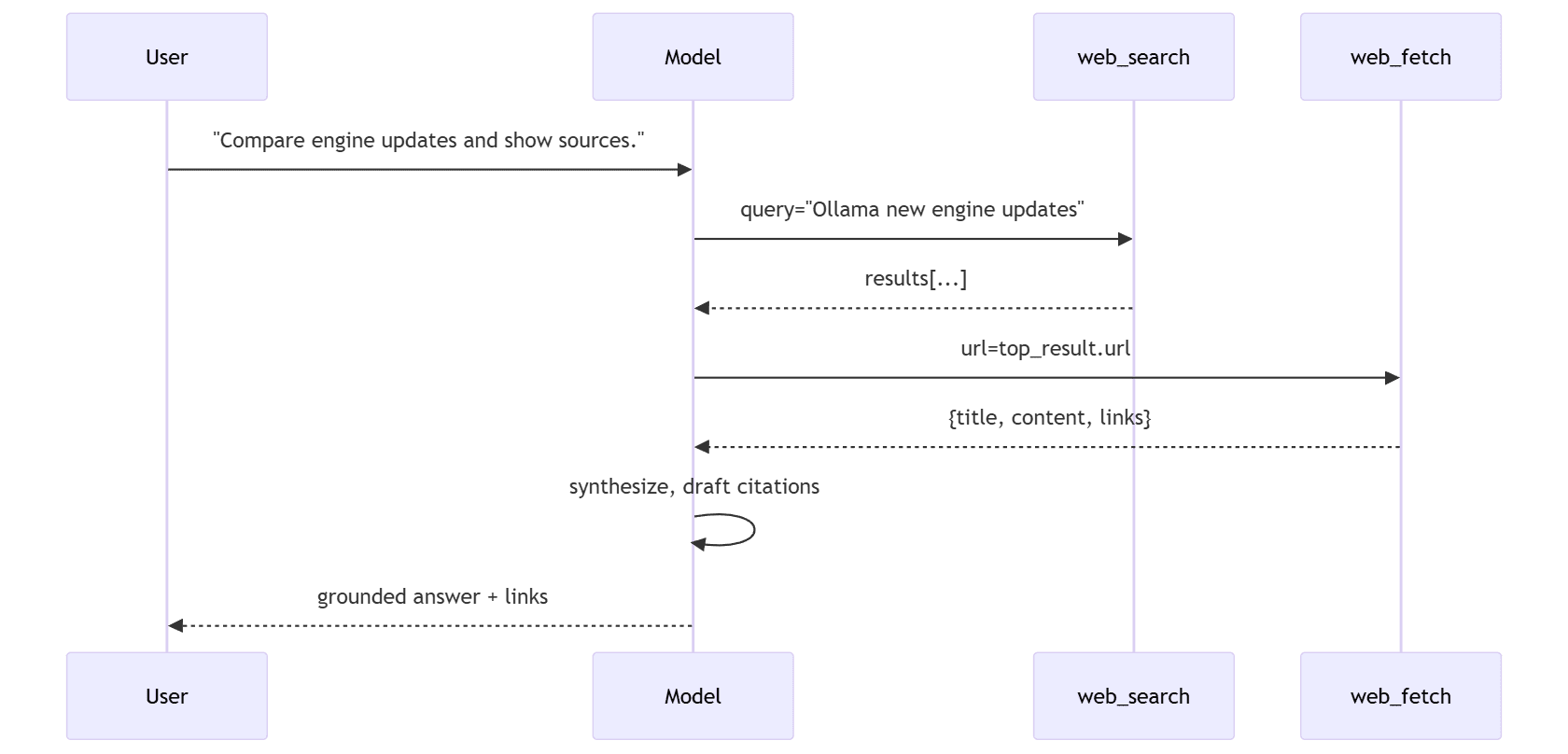
Use a short “search → pick 1–3 URLs → fetch → answer” policy for predictable latency. Escalate to more results only when confidence is low.
Performance notes
Ollama’s new model scheduling measures exact memory requirements before running a model. In practice this reduces out-of-memory failures, improves GPU utilization, and helps multi-GPU throughput. These improvements matter for search agents that pass large tool outputs back into the context window. Keep an eye on release notes for changes such as Qwen3 MoE support and tokenizer handling that can affect loading and speed.
Production checklist
- Grounding: always return the
urlalongside model claims. Teach the model to quote titles and show at least two sources when the topic is contested. - Latency control: cap search results, set timeouts on fetch, and truncate page text before sending back to the model.
- Caching: cache search results by query and fetched pages by URL. Reuse across sessions.
- Safety: disallow fetching
file://, localhost, and private networks. Sanitize and size-limit tool output. - Observability: log tool calls and token counts. Surface engine metrics when debugging throughput. The September 2025 scheduler changes are relevant when distributing across multiple GPUs.
- Model choice: small models can plan and cite if the tools return concise text; use larger models when you expect multi-document synthesis or noisy pages.
- Failure modes: detect empty or low-quality results and retry with a broader query. If fetch returns boilerplate, prefer another source.
Example: “What changed in Ollama this week?”
This single-file script shows the end-to-end pattern: search for official posts, fetch the two most relevant pages, and ask the model to summarize with citations.
import os, ollama
from ollama import chat, web_search, web_fetch
q = "Ollama engine updates this week site:ollama.com/blog"
sr = web_search(q)
def pick_urls(results, k=2):
seen = set()
out = []
for r in results:
u = r["url"]
if u not in seen and "ollama.com/blog" in u:
out.append(u); seen.add(u)
if len(out) == k:
break
return out
urls = pick_urls(sr["results"])
pages = [web_fetch(u) for u in urls]
messages = [{
"role": "user",
"content": f"Summarize the latest Ollama engine changes from these pages and provide links:\n{[p['title'] for p in pages]}\n{urls}"
}]
res = chat(model="qwen3:4b", messages=messages)
print(res.message.content)You will usually see the September 23 scheduling post and, depending on recency, the web search announcement itself.
Security and privacy
Treat tool outputs as untrusted input. Strip HTML, limit size, and log sources. If you run the agent on a server, proxy tool calls to control egress and apply allow-lists for domains. Community discussion has already raised compliance questions around data handling; expect updates to documentation and policies as adoption grows.
Why this changes your stack
Earlier I noted the engine and multimodal upgrades. Combined with Web Search and Web Fetch, you can now build compact research agents that run locally, cite sources, and scale to cloud when needed. As you iterate, keep your loop simple, your results small, and your citations visible, then layer retrieval or indexing only if your domain needs it.







