


In the early days (say the 2000s and early 2010s), machine learning was dominated by “statistical” frameworks: libraries like scikit-learn, Weka, MATLAB toolboxes, and even standalone toolkits like LIBSVM or Theano (which appeared around 2007). These tools handled regression, classification, ensemble methods, kernel methods, and so on. But as deep learning started to boom (circa 2012, with breakthroughs in convolutional neural networks, GPUs, AlexNet, etc.), the ecosystem began shifting.
Deep learning introduced demands: differentiable programming, automatic differentiation, GPU acceleration, tensor operations, dynamic graphs, distributed training, etc. Frameworks like Theano (born 2007) and later Torch (Lua) laid some groundwork, but the real turning points came with TensorFlow (launched by Google in 2015) and PyTorch (launched by Facebook’s FAIR around 2016). These made it easier for researchers and engineers to build, experiment, scale, and deploy neural networks.
Over time, as model architectures became more complex (transformers, diffusion models, multimodal networks, etc.), the frameworks also evolved (e.g. support for distributed training, model serving, hardware backends, efficiency tools). Around 2023–2025, we’re now in an era where AI frameworks are not just for training heavy models—they also must support deployment at scale, serving, edge inference, multi-agent orchestration, low-latency inferencing, hybrid hardware (CPU, GPU, NPU), portability, and composability.
So when I talk about the the most popular frameworks, I’m selecting those that combine community adoption, modern relevance, and breadth of capability (training, serving, inference, orchestration). Some are pure training frameworks, others are inference engines or orchestration systems, and a few blur the boundaries.
PyTorch
PyTorch remains a dominant player—especially in research and in model experimentation. Many new papers (especially in deep learning / transformer models) choose PyTorch because its “eager execution” and dynamic graph nature make prototyping faster and more intuitive.
Strengths & Use Cases
- Great for research and rapid experimentation.
- Strong ecosystem: libraries like Hugging Face Transformers, PyTorch Lightning, TorchServe (for serving) build around it.
- Support for distributed training, GPU/TPU backends.
Considerations
For large-scale production, raw PyTorch sometimes needs extra wrapping (e.g. for serving, scaling, versioning). But over the years, tooling has matured to bridge that gap.
TensorFlow (and its ecosystem)
TensorFlow was one of the earliest to push deep learning into production. It has a broad reach, used in industry for scalable deployments, and strong tooling support (TensorFlow Serving, TF Lite, etc.).
Strengths & Use Cases
- Good for large-scale, high-availability systems.
- Ecosystem includes TensorFlow Lite (for mobile/embedded), TensorFlow Serving, TensorFlow Hub, etc.
- Strong integration with Google Cloud and MLOps pipelines.
Recent evolution
With version 2.x and later, TensorFlow embraced eager-style execution and easy interoperability with Keras. It’s better at bridging research + production now.
Keras (Keras 3 / Keras Core)

Often people see Keras as just a “wrapper” around TensorFlow. But Keras has evolved significantly. Keras 3 (also known as Keras Core) supports multiple backends (TensorFlow, PyTorch, JAX), which makes it more flexible.
Strengths & Use Cases
- Very beginner-friendly API: good abstractions for defining neural networks.
- Enables writing model code that is portable across backends (thanks to its multi-backend support).
- Useful for rapid prototyping and educational use.
Trade-offs
Because it’s a high-level abstraction, sometimes fine-grained control (micro-optimizations, custom gradients) may require dropping into the lower-level framework.
JAX
JAX has gained a lot of momentum, especially in research settings focused on high-performance, functional-style ML. It supports just-in-time compilation, automatic vectorization, and high parallelism.
Strengths & Use Cases
- Excellent for large-scale, high-performance workloads (e.g. physics simulations, differentiable programming).
- Enables writing code in a functional style, which some prefer for clarity and optimization.
- Strong for use in research environments pushing bleeding-edge models or novel architectures.
Limitations
Less mature in serving/inference space; bridging the gap from research to production needs additional tooling.
ONNX Runtime / Inference Engines
While ONNX (Open Neural Network Exchange) is a format rather than a framework per se, ONNX Runtime serves as a high-performance inference engine. Many models (from PyTorch, TensorFlow, etc.) are exported to ONNX and then run via ONNX Runtime.
Strengths & Use Cases
- Hardware-agnostic, works on CPU, GPU, and other accelerators.
- Often used in deployment pipelines: export a trained model, run it via ONNX.
- Low-latency inference, optimized kernels.
Considerations
ONNX is for inference; it does not (on its own) provide training capabilities. Also, not all operations in all models convert cleanly to ONNX, so there can be compatibility challenges.
OpenVINO
OpenVINO is focused on optimizing and deploying inference, especially on Intel hardware (CPUs, integrated GPUs, NPUs). Its latest version (2025.3) continues to push improvements.
Strengths & Use Cases
- Excellent for edge deployment, inference at low latency, and leveraging Intel’s hardware capabilities.
- Works by converting models (TensorFlow, ONNX, PyTorch) into optimized intermediate representations, then executing them.
- Comes with a “Model Server” (OpenVINO Model Server, OVMS) to host inference endpoints.
Limitations
It is relatively hardware-specific (Intel-focused). If you plan to serve across heterogeneous hardware (NVIDIA GPU, Apple silicon, etc.), you may need fallback mechanisms or other inference engines.
Kubeflow (for ML orchestration / MLOps)
Kubeflow is not a neural network library—but it is essential in modern ML workflows. It is a platform for building, deploying, and managing ML workflows on Kubernetes.
Strengths & Use Cases
- Integrates model training, hyperparameter tuning, serving, pipelines, notebooks, etc.
- Good fit when you’re operating in a cloud-native environment and need scalability, reproducibility, versioning, and orchestration.
- Flexibility: components (e.g. Pipelines, Katib) can be used independently.
Challenges
It requires operational overhead (Kubernetes, cluster management). Also, it’s not a drop-in solution for small-scale experiments.
PyTorch Lightning (and similar high-level wrappers)
While not a framework in the sense of “you can’t train without it,” PyTorch Lightning is important because it abstracts boilerplate and helps structure code better. It simplifies distributed training, logging, checkpointing, etc. Many teams choose it for mature projects.
It sits on top of PyTorch and helps with cleaner, more maintainable code.
LangChain (for LLM/agent orchestration)
This is a newer kind of framework, tailored for LLM-powered applications and agents. LangChain helps you build systems where you chain model calls, add memory, integrate tools, manage workflows, etc.
Strengths & Use Cases
- Excellent for applications that need to go beyond a single prompt: memory, tool calls, reasoning loops, multi-step workflows.
- Helps glue together LLMs with APIs, retrieval systems, database access, etc.
- In 2025, LangChain supports multi-agent orchestration, memory management, observability (LangSmith), and production deployment (LangGraph).
Considerations
It is not meant for low-level training of models—it operates at the application layer. Also, architecture decisions (how many agents, tool types) still require human design.
(Bonus / Rising) Agent Lightning or Similar Agent Training Frameworks
In cutting-edge research, new frameworks are emerging to better train agents built on top of LLMs using reinforcement learning or structured feedback. One example is Agent Lightning (recently proposed) that decouples agent execution from training, letting you plug in different agents and environments.
While not yet mainstream, such frameworks may become more important as agents in production move from scripted workflows to more adaptive, self-learning systems.
Visual: how these frameworks relate
Here’s a mental model that shows roughly how these frameworks occupy layers in the AI stack:
graph LR
subgraph Training / Model Building
PyTorch
TensorFlow
JAX
Keras
end
subgraph Inference / Serving
ONNX_Runtime
OpenVINO
end
subgraph Orchestration / MLOps
Kubeflow
PyTorch_Lightning
end
subgraph LLM / Agent Layer
LangChain
Agent_Lightning
end
PyTorch --> ONNX_Runtime
TensorFlow --> ONNX_Runtime
ONNX_Runtime --> OpenVINO
Kubeflow --> PyTorch
Kubeflow --> TensorFlow
LangChain --> ONNX_Runtime
LangChain --> PyTorch
Agent_Lightning --> LangChain
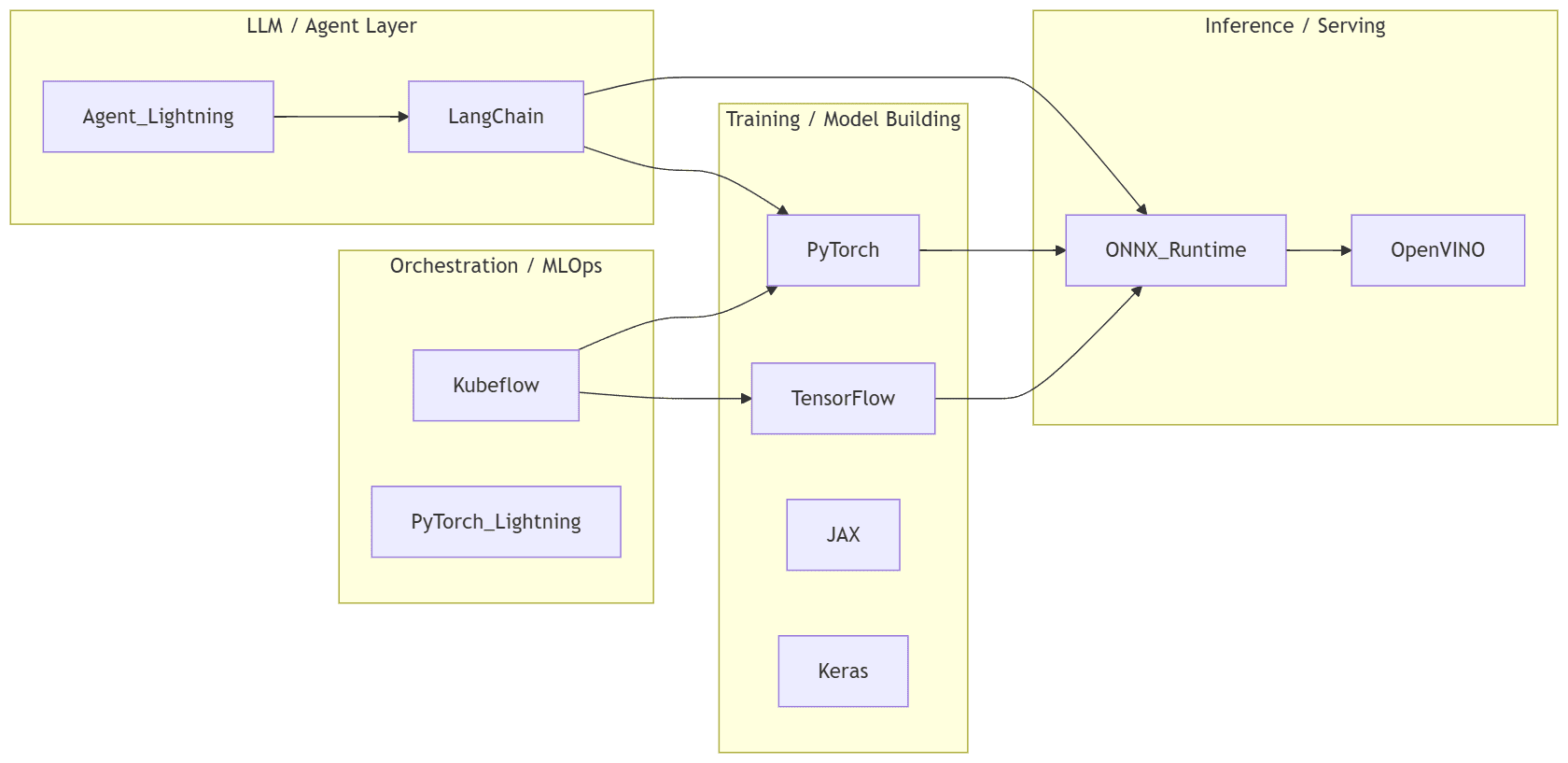
This is a simplified mapping. In practice, many frameworks interoperate and you’ll often “mix and match” depending on your pipeline.
Choosing the Right Framework for Your Project
Given all these choices, how do you decide? Here’s a rough guideline:
- If you’re doing research / experimenting: start with PyTorch or JAX (or PyTorch + PyTorch Lightning).
- If you’re targeting production / deployment, consider using TensorFlow or exporting to ONNX Runtime / OpenVINO (especially for inference).
- If you need to orchestrate pipelines, scalable training, autoscaling, etc., use something like Kubeflow or MLOps tools.
- If your project is an AI agent or LLM application (e.g. chatbots, multi-step workflows), LangChain becomes almost indispensable.
- If you’re working at the edge or on hardware-constrained devices, frameworks like OpenVINO or ONNX-based inference engines shine.
- If you’re pushing into adaptive agents that can learn over time, keep an eye on newer frameworks like Agent Lightning.
One practical approach is to build your prototype using PyTorch + LangChain, then when you’re ready to scale, export key models to ONNX, wrap them with an inference engine (ONNX Runtime or OpenVINO), and manage deployment via Kubeflow.
Final Thoughts & Outlook
We’ve come a long way from libraries that only handled linear algebra and logistic regression. By 2025, the AI framework landscape is rich and layered:
- You’ve got core training frameworks (PyTorch, TensorFlow, JAX)
- Inference engines (ONNX Runtime, OpenVINO)
- Orchestration platforms (Kubeflow, Lightning)
- Agent/LLM orchestration and orchestration frameworks (LangChain, Agent Lightning)
Transitions between these layers are increasingly smooth. For example, Keras 3 is striving to let you write code once and run it on multiple backends (TensorFlow, PyTorch, JAX).
Also, the evolution of inference tooling (e.g. OpenVINO’s support for GenAI, OVMS, etc.) shows that deployment is not an afterthought—it’s central.
When you go forward, it’s less about picking a single “universal” framework, and more about assembling the right stack: training + inference + orchestration + agent layer that fit your problem domain, latency constraints, hardware, and future growth.






