


DeepSeek has quietly pushed its research agenda forward with the release of DeepSeek-V3.2-Exp, an experimental intermediate model that builds on V3.1-Terminus and introduces a novel DeepSeek Sparse Attention (DSA) mechanism.
For those tracking the company’s rapid-fire cadence—from the 671B-parameter MoE V3 and its hybrid-thinking V3.1 upgrade, to the stability-focused V3.1-Terminus—this marks the first official release labeled “experimental.” It signals DeepSeek’s intent to probe architectural changes before locking in the design of its next-generation models.
The central innovation is DeepSeek Sparse Attention (DSA), a fine-grained sparse attention scheme engineered to cut training and inference costs for long-context workloads without degrading output quality. Sparse attention is not a new research direction, but DeepSeek is claiming a “first” in delivering fine-grained sparsity at scale while maintaining near-parity in benchmark accuracy.
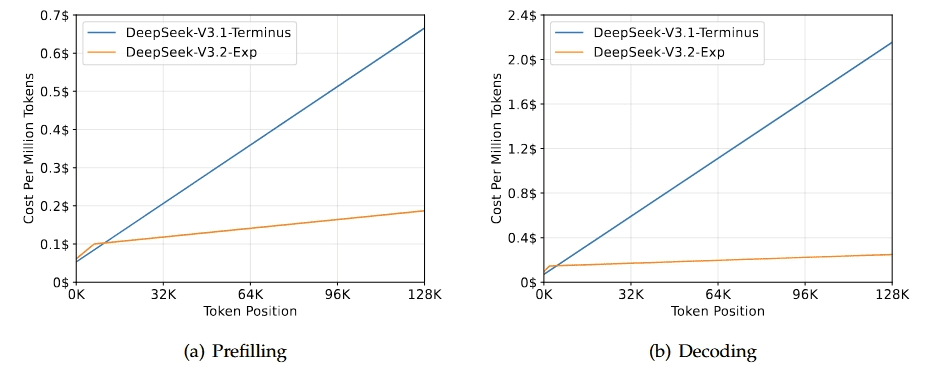
To isolate the effect of DSA, the team reports that V3.2-Exp was trained under the same configurations as V3.1-Terminus. The result: benchmarks remain broadly consistent, with some modest shifts. On reasoning-heavy tasks:
- MMLU-Pro: unchanged at 85.0
- GPQA-Diamond: 79.9 vs. 80.7
- AIME 2025: slight improvement, 89.3 vs. 88.4
- Codeforces: notable jump, 2121 vs. 2046
On agentic tool-use tasks, scores also hover around parity, with BrowseComp actually improving from 38.5 to 40.1.
In other words: no accuracy collapse, and in some areas, a touch better—evidence that sparse attention can be deployed without sacrificing quality.
Why It Matters
DeepSeek has consistently pursued efficiency as a strategic differentiator: Multi-Head Latent Attention (MLA) for compressed KV caching, DeepSeekMoE for sparse expert routing, and auxiliary-free load balancing in V3. The introduction of DSA extends this ethos into long-context handling—a bottleneck for both research and deployment at scale.
If validated, this technique could materially reduce the GPU-hours required for training and inference, reinforcing DeepSeek’s reputation for achieving “more with less.” That narrative already unsettled competitors earlier this year when reports of DeepSeek’s training efficiency sparked industry and geopolitical reactions.
As with prior releases, V3.2-Exp ships with tooling to help researchers get hands-on:
- Inference demo code with updated conversion scripts
- Support for model-parallel training runs
- Open-source kernel releases: TileLang for readability, DeepGEMM for performance, and FlashMLA extensions to support sparse attention
By surfacing both readable kernels and performance-focused ones, DeepSeek is telegraphing its dual strategy: pushing cutting-edge research while seeding community adoption.
While V3.2-Exp is not a production model, it’s a preview of what might anchor V4. If DSA proves stable at scale, expect DeepSeek’s next flagship to integrate sparse attention natively, potentially unlocking even longer context windows at lower cost.







