If you’ve been watching the AI boom lately, you know that the major breakthroughs in model training and inference often hinge on raw hardware horsepower — especially GPUs. Every generation, new architectures push what’s possible: larger models, faster inference, more efficient memory handling. As AI becomes more accessible, developers, startups, and researchers all ask: “Where can I rent a GPU that doesn’t break the bank, but still gives me bleeding-edge performance?”
DigitalOcean has long been known for simplicity, clarity, and developer friendliness. For years, it offered cloud VMs (“Droplets”), managed databases, and container hosting, appealing to smaller teams and individual builders who didn’t want to wrestle with AWS complexity. But as AI/ML workloads became central in many applications, the natural question was: can DigitalOcean compete when it comes to high-end GPUs?
Over the last year, the answer has evolved, and the state of play is now interesting. Let me walk you through how we got here, where we stand, and how you can use (or not use) H200 on DigitalOcean today.
What Is the NVIDIA H200?

To understand what H200 offers, it’s helpful to see it as a next evolutionary step beyond NVIDIA’s prior generation (H100). It’s built on the Hopper microarchitecture but upgrades key subsystems.
Key technical highlights:
- Memory & Bandwidth: Uses HBM3e memory, achieving up to 141 GB of memory per GPU. Memory bandwidth reaches ~4.8 TB/s.
- Tensor / Transformer Engine: It supports the 4th-generation tensor cores, with mechanisms optimized for transformer models (e.g. dynamic precision switching between FP8/FP16).
- Multi-Instance GPU (MIG): H200 can be partitioned into secure, isolated slices (up to 7 MIGs, each ~16.5 GB). This allows multiple workloads to share one GPU while maintaining hardware isolation.
- Interconnects (NVLink / NVSwitch): Maintains support for NVLink, enabling very high interconnect speeds useful in multi-GPU setups.
Because of these enhancements, H200 is especially powerful for large models (when memory is a limiting factor), inference workloads where throughput and latency matter, and scenarios where splitting the GPU across tenants matters.
| Spec | H100 (SXM) | H100 NVL (PCIe pair-ready) | H200 (SXM) | H200 NVL (PCIe) | Delta (H200 SXM vs H100 SXM) |
|---|---|---|---|---|---|
| Memory type | HBM3 | HBM3 | HBM3e | HBM3e | — |
| Memory capacity | 80 GB | 94 GB | 141 GB | 141 GB | ≈1.76× (≈“~1.8×”) |
| Peak mem. bandwidth | 3.35 TB/s | 3.9 TB/s | 4.8 TB/s | 4.8 TB/s | ≈1.43× (≈“~1.4×”) |
In direct head-to-head with H100, H200 offers roughly ~1.4× the memory bandwidth and ~1.8× memory capacity in many deployments.
DigitalOcean’s GPU Journey (Before H200)
Before the H200 era, DigitalOcean had already dipped its toes (or more) into GPU offerings:
- GPU Droplets: These are virtual machines (“Droplets”) with attached GPU resources (NVIDIA GPUs) for AI/ML usage.
- H100 support: DigitalOcean’s Gradient™ AI GPU Droplets earlier offered the H100 GPU as one of their high-end options.
- Other GPUs: In addition to flagship GPUs, DigitalOcean offered more modest ones (e.g. RTX series, Ada generation GPUs) for lighter workloads or inference use cases.
- Bare metal GPU offerings: For users needing maximum performance, DigitalOcean also made bare metal GPU servers available. Prior to H200, these were typically built around H100 or equivalent GPUs.
This gradual layering of GPU options primed the platform to accept the next generation — H200.
Does DigitalOcean Offer NVIDIA H200? — Current State
The short answer is: Yes — DigitalOcean now offers NVIDIA H200 GPUs, in virtualized GPU Droplets with custom configuration options. However, availability, pricing, and constraints should be understood carefully.
GPU Droplets with H200
DigitalOcean recently made it possible to create GPU Droplets accelerated by NVIDIA HGX H200.
Some highlights:
- The on-demand price is approximately $3.44 per GPU per hour.
- You can launch droplets with 1 GPU or up to 8 GPUs (i.e., “H200×8”) for larger workloads.
- Each 1-GPU Droplet with H200 provides 141 GB GPU memory, 240 GiB of host memory, and is backed by NVMe storage.
So yes, if you use the GPU Droplet path, you can get H200 support today.
Regions, Constraints & Infrastructure Rollout
It’s not yet universal everywhere. As of now:
- GPU Droplets with H200 are available in select regions (e.g. NYC2) with plans to expand.
- In March 2025, DigitalOcean announced a partnership with Flexential to set up high-density GPU infrastructure in their Atlanta site, which will include support for NVIDIA H200 among others.
- That expansion is intended to scale the capacity so more users, regions, and workloads can utilize H200 power.
- Because of power, cooling, and density constraints, not every data center can host H200 immediately — so some regions may lag or be unavailable.
In short: your ability to use these GPUs depends on region, capacity, and timing. You also have to consider the fact that AI is extremely popular and the demand for high-end GPUs such as the H200 is absolutely insane!
It can be quite difficult to find a free slot for H200 on DigitalOcean, make sure you have an account created so you can monitor their availability!
Use Cases, Strengths & Limitations
Now that we know H200 is on the platform, when is it a good idea to deploy it for your project — and when might it be overkill (or inefficient)? At the end of the day, they can get a little pricey if you plan to use them for extended periods of time.
Strengths & Ideal Use Cases
- Large model training / fine-tuning: When model size is memory bound (e.g. billions of parameters), H200’s 141 GB memory gives headroom.
- High-throughput inference on large models: Inference of LLMs with large contexts benefits from high bandwidth and lower latency.
- Multi-tenant / subdividing workloads: Using MIG, you can partition one H200 for multiple concurrent tasks, each isolated.
- Simpler scaling across GPUs: Because interconnects and NVLink are strong, multi-GPU workloads (data parallel, model parallel) become more efficient.
- Transition planning: If you already have workloads on H100 or smaller GPUs, moving to H200 can bring performance gains without drastic architectural changes.
Limitations & Trade-Offs
- Cost: At $3.44 GPU/hr, it is a premium option. For lighter tasks, cheaper GPUs might be more cost effective.
- Overprovisioning risk: If your workload doesn’t need the memory or bandwidth, you may pay for performance you don’t use.
- Availability / waiting: In some regions, H200 capacity may be limited, leading to queuing or unavailability.
- Software / ecosystem maturity: Though newer GPUs tend to be supported fairly quickly, sometimes niche libraries or custom kernels may lag.
Thus, it’s important to match the workload to the hardware — avoid assuming “bigger is always better.”
How to Get Started / Example Workflow
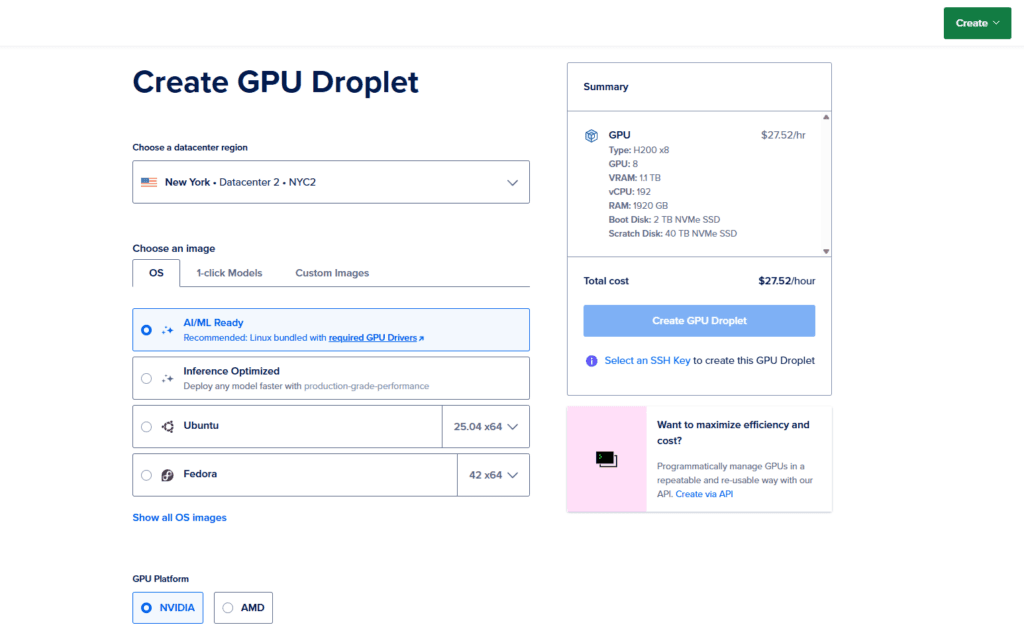
Let me walk you through how you might start using an H200 GPU on DigitalOcean and some simple example code setup.
Step 1: Provision the GPU Droplet
From DigitalOcean’s control panel or API:
- Choose Gradient → GPU Droplets
- Select H200 as the GPU type
- Pick the number of GPUs (1 or up to 8)
- Select region (must be one where H200 is available)
- Choose size (memory, vCPUs)
- Create and wait for it to boot
Step 2: Install Drivers & Libraries
Once your machine is up, install NVIDIA drivers, CUDA, and your ML stack. For example (on Ubuntu):
# Example: install CUDA toolkit & drivers
sudo apt update
sudo apt install -y nvidia-driver-### # choose version matching H200 support
sudo reboot
# After reboot
nvidia-smi
# should show H200 with memory, utilization, etc.
# Install CUDA toolkit
sudo apt install -y cuda-toolkit-##.#
# Then in Python environment install PyTorch, etc.
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu## # matching CUDA(Replace ### and ##.# with the appropriate driver and toolkit versions.)
Step 3: Run a Simple ML Model Example
Here’s a minimal PyTorch example to confirm GPU works:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to("cuda")
inputs = tokenizer("Hello, DigitalOcean H200!", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))If this prints a coherent output without GPU errors, your GPU setup is likely functional.
Step 4: Performance Tuning & Best Practices
- Experiment with batch sizes, gradient accumulation, mixed precision (FP16 / FP8)
- Use MIG slices if your workload can be partitioned — avoids contention
- Monitor GPU metrics (utilization, memory, temperature) via
nvidia-smi,nvtop, or tools - When scaling to multi-GPU, use distributed frameworks (PyTorch Distributed, Accelerate, DeepSpeed)
- Tune I/O: ensure data pipelines (disk, network) keep up so GPU isn’t idle
Alternatives & Comparisons
It helps to see how H200 on DigitalOcean stacks up to alternatives.
- Other GPU options on DigitalOcean:
– H100 (cheaper, still powerful as shown in the table earlier)
– RTX 4000 Ada, RTX 6000 Ada, L40S — useful for inference, graphics, mixed workloads
– AMD Instinct (MI300X) also offered by DigitalOcean - Other cloud providers’ H200 offerings: Some hyperscalers or specialized AI clouds may also support H200 or equivalents (or upcoming GPU generations). Always compare pricing, network, region availability, and support.
- Hybrid / multi-cloud approach: Use DigitalOcean’s H200 where your workload fits (e.g. inference near your user base), and drop into other providers for overflow or training.
- On-prem or colocation GPU: If you have steady sustained load, owning hardware may sometimes be cheaper in the long run — though it implies management, cooling, reliability overhead.
Future Outlook & Considerations
Looking ahead:
- DigitalOcean is clearly investing heavily in GPU infrastructure (e.g. Flexential partnership) to expand capacity.
- More data centers will likely receive H200 support over time, reducing geographic constraints.
- Newer GPU generations may arrive (beyond H200), so flexibility and upgrade paths matter.
- As AI frameworks evolve, software support for features like FP8, pipeline parallelism, efficient sparse operations may increase, making H200 even more valuable.
- Watch for supply chain / chip scarcity or energy/cooling bottlenecks — these could impose limits.
It’s a promising path, but don’t assume unlimited availability or cost stability forever.
Summary
Yes — DigitalOcean now does offer NVIDIA H200 GPUs. While availability is still expanding and subject to region constraints, it’s real and already live in pockets. The pricing is premium, but aligned with what you’d expect for such high-end accelerators.
If your workload demands large memory, high throughput, or low-latency inference — H200 is a strong match. But if you’re doing smaller models or infrequent runs, you may be better served by more modest GPUs to reduce costs. Always check region availability first.