


On October 7, 2025, Google announced the public preview of Gemini 2.5 Computer Use, an AI model designed to control web browsers like a human user—clicking, typing, dragging, filling forms, and navigating interfaces.
The new model extends the capabilities of the Gemini family by enabling agents to interact directly with graphical user interfaces (GUIs) instead of relying solely on structured APIs.
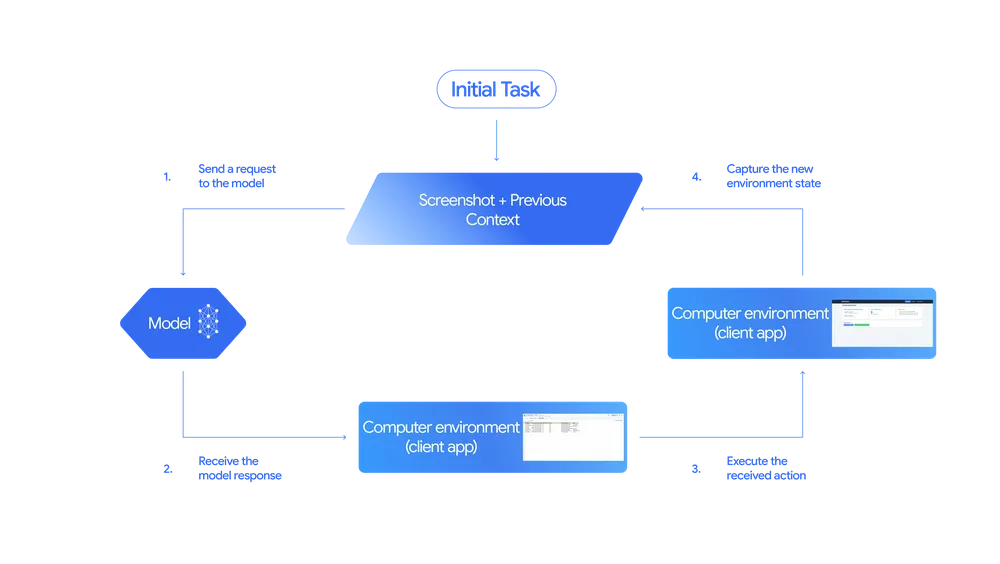
Gemini 2.5 Computer Use operates via a looped interaction mechanism:
- The system sends the user prompt, a screenshot of the current GUI, and recent action history to the model.
- The model analyzes that context and returns a proposed UI action (e.g., “click this button,” “type in this field”). For certain sensitive actions, it may request user confirmation.
- The client application executes that UI action in the browser.
- A new screenshot is captured and sent back to the model, and the loop repeats until the task is completed or an error or safety stop occurs.
This “look → think → act → verify” loop mimics how humans interact with interfaces, allowing the model to handle multi-step workflows.
Naturally, this initial version has extremely limited scope and other limitations:
- The Computer Use model is primarily optimized for web browser control, though Google notes it shows promise in mobile UI tasks as well.
- It is not yet optimized for controlling desktop operating systems or low-level OS tasks.
- The model exposes a
computer_usetool via the Gemini API, allowing developers to embed it into applications. - Because it is a preview, Google advises caution in using it for tasks involving critical decisions or sensitive data, and recommends supervision.
Capabilities & benchmarks
Gemini 2.5 Computer Use introduces a set of native UI actions, such as:
- clicking or dragging elements
- typing text
- filling out form fields, selecting from dropdowns or filters
- performing navigation (URL changes, scrolling, etc.)
In Google’s benchmark comparisons, Gemini 2.5 Computer Use outperformed leading alternatives (including other AI agents) on web and mobile control tasks, with higher accuracy and lower latency. One benchmark cited is the Browserbase harness for Online-Mind2Web, in which Gemini 2.5 Computer Use achieved both low latency and strong accuracy.
Google also shared demo scenarios, such as:
- Retrieving pet records from a webpage, filling them into a CRM application, and scheduling follow-up appointments.
- Organizing virtual sticky-note boards by dragging and placing task cards into categories.
These demos highlight the model’s ability to reason about interface layouts and perform multi-step workflows autonomously (with safeguards in place).
Given the risks associated with autonomous UI control, Google has built in safety mechanisms:
- A per-step safety service evaluates each proposed action for potential risk before execution.
- Developers can specify which classes of actions should require user confirmation (e.g., purchases or destructive operations).
- Additional documentation, system cards, and guidelines are provided to help developers enforce guardrails.
Availability & how to get started:
- The Gemini 2.5 Computer Use model is being released in public preview and is accessible via the Gemini API in Google AI Studio and Vertex AI.
- Google provides a demo environment (via Browserbase) so developers can test the model’s capabilities.
- Google advises developers to run agents in sandboxed or controlled environments (e.g., isolated browser profiles, VMs) for security during development.
Significance and outlook
The release of Gemini 2.5 Computer Use marks a step toward more capable AI agents that can interact directly with software designed for humans. Many web interfaces do not expose APIs for every function — filling forms, navigating multi-page workflows, handling UI logic — and this model addresses precisely those gaps.
By offering a generalized way to automate UI tasks (beyond brittle scripts or custom bots), Gemini 2.5 Computer Use could accelerate workflows in areas like:
- web form automation
- web application testing and QA
- data gathering from sites without structured APIs
- agentic assistants that act autonomously in browser environments
However, given that the model is still in preview and comes with safety caveats, it will likely be adopted first in controlled, lower-stakes scenarios. Over time, improvements in reliability, safety, and feature coverage may broaden its real-world applications.







