


IBM Research has officially released Granite-Docling-258M, a compact vision-language model (VLM) for converting documents into machine-readable formats while preserving complex layout, structure, tables, equations, lists, and other document elements.
With just 258 million parameters, Granite-Docling is designed to perform comparably to much larger systems, offering cost and efficiency advantages. Unlike conventional OCR approaches that tend to flatten structure, Granite-Docling outputs a richly annotated representation of page structure (called DocTags) which retains spatial and semantic relationships.
Granite-Docling builds on earlier work in the Docling ecosystem. It replaces the SmolDocling-256M preview’s backbone (SmolLM-2) with a Granite 3–based architecture and upgrades the visual encoder from SigLIP to SigLIP2. The new version addresses prior issues such as token repetition or incomplete parses through more rigorous dataset filtering, annotation cleanup, and improved training strategies.
Internally, the model combines a SigLIP2 visual encoder (patch-based) with a Granite 165M language component, integrated via a connector (e.g. pixel shuffle) in a multimodal architecture. During training, the model was supervised to generate DocTags directly, so it is familiar with that structured format from the start.
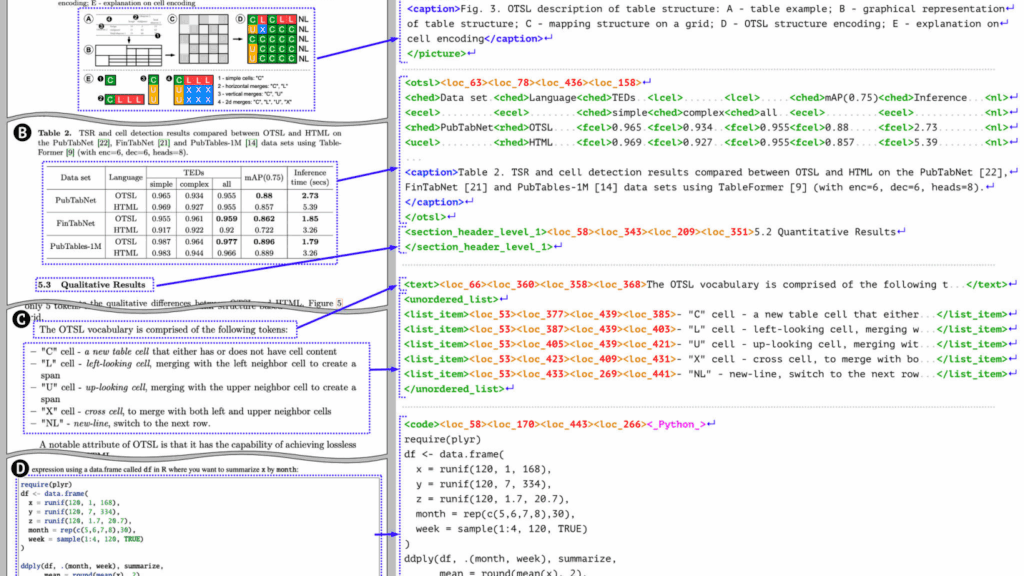
At the heart of Granite-Docling’s approach is DocTags, a structured tagging format that explicitly encodes each page element (text blocks, tables, code, equations, captions, forms, etc.), their bounding boxes, reading sequence, and relationships. This explicit separation of content and structure enables clean downstream conversion to Markdown, HTML, JSON, or integration into LLM-based pipelines (e.g. retrieval-augmented generation). Because DocTags defines a richer vocabulary for document layouts than general markup languages, it avoids many ambiguities found in naïve conversions.
IBM reports that on standard document understanding benchmarks, Granite-Docling matches or exceeds the performance of many larger proprietary systems, particularly in table structure recognition, equation parsing, and layout retention. For example, its TEDS (structure) and TEDS (with content) metrics on FinTabNet are much higher compared to prior SmolDocling.
Granite-Docling also introduces experimental support for non-Latin scripts such as Arabic, Chinese, and Japanese. These capabilities remain early-stage and have not yet been validated for production use. IBM positions the model as part of a broader document AI pipeline (e.g., in the Docling library), especially for tasks like document question answering, layout-aware conversion, and preprocessing for RAG systems.
Granite-Docling-258M is released under the Apache 2.0 license and is available via Hugging Face. IBM intends future variants with higher parameter counts, up to about 900 million, while keeping models under 1 billion parameters. Another key part of the roadmap involves expanding evaluation efforts (via Docling-eval) and tighter integration of DocTags with IBM’s watsonx.ai suite.







