


You ship a Next.js app to Cloudflare Workers. The homepage renders, so far so good. Then you click around, reload a few times, and suddenly you’re staring at a Cloudflare captcha or a gray error screen that says 1102. That code means your Worker gobbled up more CPU than Cloudflare allows for a single request. If you’re fetching lots of data on the server, chaining internal API routes, or firing a bunch of parallel subrequests, you can hit that limit surprisingly fast.
Cloudflare’s docs are blunt about it: error 1102 is raised when a Worker exceeds the CPU time limit for the invocation. The limit depends on your plan and any custom cap you set. On today’s standard pricing model, Cloudflare measures and bills CPU time and allows you to configure a per-invocation CPU cap. Legacy migrations often default to 50 ms unless you change it. Either way, when your server logic is heavy, you trip the wire.
At the same time, Next.js on Workers is newer than “classic” Node hosting. The recommended route is to build with the OpenNext Cloudflare adapter so Server Components and routing play nicely with Workers’ runtime. That gets your app running at the edge, but it does not magically make expensive backend code cheap. You still need to structure data fetching for the edge.
There is another tripwire: subrequests. Each fetch() your Worker makes counts toward a per-request subrequest cap. On Free that cap is 50; on Paid it is much higher, but you can still saturate CPU with a burst of 60+ OGP scrapes in parallel, as it happened to me in my project.
If this sounds like your app, let’s fix it.
What “1102” actually means for your Next.js app
In plain terms: your request handler, including any internal API routes your page hits, used too much CPU. Tight loops over dozens of network calls, heavy parsing, or doing the same work again and again on every navigation can push you over.
Key moving parts to be aware of today:
- CPU time limit per invocation raises 1102 if exceeded. Paid plans allow you to tune CPU caps; legacy Workers might still be capped at 50 ms until you update.
- Subrequests are limited per request. Bursty parallel OGP fetches can bump into limits and also inflate CPU time.
- Next.js on Workers is supported via OpenNext and the Workers or Pages runtimes. It works great, but you must lean on static generation and caching to keep edge work light.
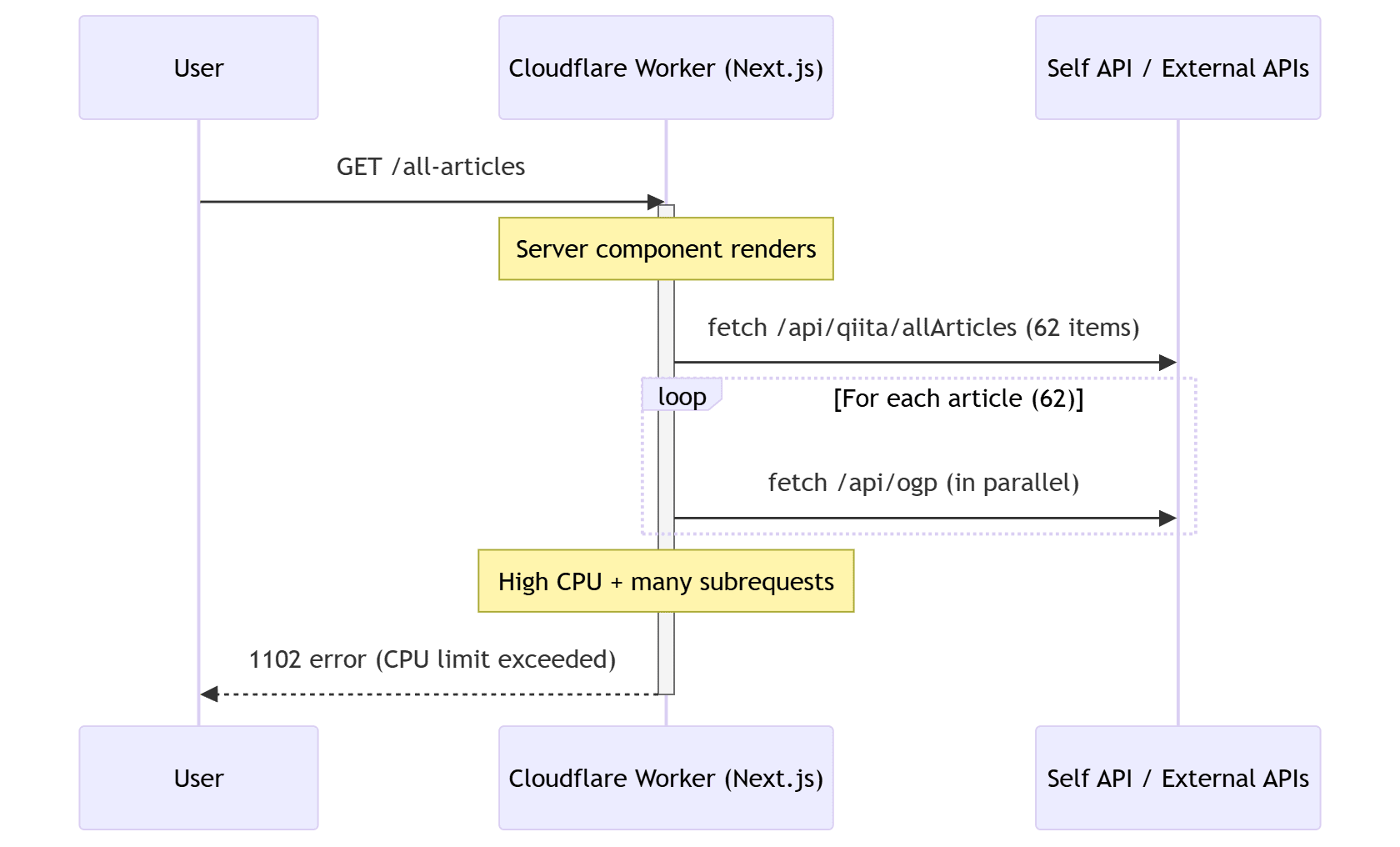
Here’s a quick picture of what goes wrong when a page fetches everything dynamically in one go:
sequenceDiagram
participant U as User
participant W as Cloudflare Worker (Next.js)
participant API as Self API / External APIs
U->>W: GET /all-articles
activate W
Note over W: Server component renders
W->>API: fetch /api/allArticles (60 items)
loop For each article (60)
W->>API: fetch /api/ogp (in parallel)
end
Note over W: High CPU + many subrequests
W-->>U: 1102 error (CPU limit exceeded)
deactivate W
The fix: move work out of the request path and into the build or a schedule
Start by asking: does this data need to be fetched at request time? If the answer is “not really,” then push it to build time or a scheduled job and serve it as static JSON. For anything that must remain dynamic, reduce fan-out and add caching.
1) Prefer Static Site Generation for heavy lists
If your page composes a list of your own articles and their OGP images, generate that once. Next.js provides SSG for pages and Route Handlers. Serving a prebuilt JSON blob is almost free at the edge, because CDNs can cache it.
Build step script that fetches all articles and writes data/all-articles.json:
// scripts/fetch-all-articles.ts
// Run with: tsx scripts/fetch-all-articles.ts
import fs from "node:fs/promises";
type Article = {
id: string;
title: string;
body: string;
likes_count: number;
stocks_count: number;
url: string;
};
async function main() {
const res = await fetch("https://dropletdrift.com/api/v2/authenticated_user/items?per_page=100"); // adjust to your endpoint
if (!res.ok) throw new Error(`Failed to fetch articles: ${res.status}`);
const items = (await res.json()) as any[];
const articles: Article[] = items.map((i) => ({
id: i.id,
title: i.title,
body: i.body || "",
likes_count: i.likes_count ?? 0,
stocks_count: i.stocks_count ?? 0,
url: i.url,
}));
await fs.mkdir("data", { recursive: true });
await fs.writeFile("data/all-articles.json", JSON.stringify(articles, null, 2));
console.log(`Wrote ${articles.length} articles to data/all-articles.json`);
}
main().catch((e) => {
console.error(e);
process.exit(1);
});Fetch OGP in a bounded-concurrency pool and write data/ogp-data.json:
// scripts/fetch-ogp.ts
import fs from "node:fs/promises";
type Article = { id: string; url: string };
type Ogp = { id: string; ogpImage?: string };
async function getOgp(url: string): Promise<string | undefined> {
const res = await fetch(`https://dropletdrift.com/http://ogp.me/?url=${encodeURIComponent(url)}`); // replace with your OGP microservice
if (!res.ok) return undefined;
// parse HTML or JSON returned by your OGP endpoint
const html = await res.text();
const match = html.match(/property=["']og:image["']\s+content=["']([^"']+)["']/i);
return match?.[1];
}
async function pool<T, R>(items: T[], limit: number, worker: (t: T) => Promise<R>) {
const ret: R[] = [];
let i = 0;
const run = async () => {
for (; i < items.length; i++) {
const idx = i;
i++;
ret[idx] = await worker(items[idx]);
}
};
await Promise.all(Array.from({ length: Math.min(limit, items.length) }, run));
return ret;
}
async function main() {
const articles = JSON.parse(await fs.readFile("data/all-articles.json", "utf8")) as Article[];
const ogp = await pool(articles, 5, async (a) => ({ id: a.id, ogpImage: await getOgp(a.url) } as Ogp));
await fs.writeFile("data/ogp-data.json", JSON.stringify(ogp, null, 2));
console.log(`Wrote OGP for ${ogp.length} articles`);
}
main().catch((e) => {
console.error(e);
process.exit(1);
});Use the JSON at runtime with a Server Component that does no network work:
// app/all-articles/page.tsx (Next.js 15+ App Router)
import allArticles from "@/data/all-articles.json";
import ogpData from "@/data/ogp-data.json";
type Article = {
id: string;
title: string;
body: string;
likes_count: number;
stocks_count: number;
url: string;
};
export default function AllArticlesPage() {
const articles = allArticles as Article[];
const ogpMap = new Map(ogpData.map((o: any) => [o.id, o.ogpImage as string | undefined]));
const processed = articles.map((a) => ({
id: a.id,
title: a.title,
body: `${a.body.slice(0, 150)}...`,
likes_count: a.likes_count,
stocks_count: a.stocks_count,
url: a.url,
ogpImage: ogpMap.get(a.id),
}));
return (
<main className="mx-auto max-w-3xl p-6 space-y-6">
{processed.map((a) => (
<article key={a.id} className="space-y-2">
<a href={a.url}><h2 className="text-xl font-semibold">{a.title}</h2></a>
{a.ogpImage && <img src={a.ogpImage} alt="" className="w-full rounded-xl" />}
<p>{a.body}</p>
<p className="text-sm opacity-70">👍 {a.likes_count} | 📌 {a.stocks_count}</p>
</article>
))}
</main>
);
}This path removes the heavy fetches from your request. It also plays perfectly with Cloudflare’s edge cache for static assets and JSON.
2) If something must stay dynamic, cache and throttle
If you truly need to hit an external API on request, do two things:
- Cache the response. On Workers, proper cache headers and the Cache API work together to remove repeat CPU burn.
- Bound concurrency. Keep parallel fetches to a small number like 5. This reduces per-request CPU spikes and helps you stay under subrequest caps.
A minimal Worker-side cache example for a Route Handler:
// app/api/news/route.ts
export async function GET() {
const url = new URL("https://dropletdrift.com/api/news");
const res = await fetch(url.toString(), {
// honor CDN caching if upstream sends Cache-Control
cf: { cacheEverything: true, cacheTtl: 600 },
});
// In Next.js route handlers on Cloudflare, the platform fetch layer cooperates with CDN cache.
return new Response(res.body, {
headers: {
"Content-Type": "application/json",
"Cache-Control": "public, max-age=600, s-maxage=600, stale-while-revalidate=60",
},
});
}3) Keep subrequests and CPU budgets in mind
Making 60 OGP calls at once on page load is expensive. Cap the fan-out, or precompute. Remember: Workers enforce a subrequest limit per request and they meter CPU time per invocation. If you migrated from older pricing, double-check your CPU cap because it may be set to 50 ms by default.
Automate the prebuild step with GitHub Actions on a schedule
You want fresh data without hitting APIs on every user request. Put the scripts/* tasks into a scheduled workflow that commits updated JSON. GitHub Actions supports cron schedules in UTC and will run on the default branch.
# .github/workflows/refresh-data.yml
name: Refresh article data
on:
schedule:
- cron: "5 * * * *" # every hour at :05 UTC
workflow_dispatch: {} # allow manual runs
permissions:
contents: write
jobs:
build-data:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: "lts/*"
- name: Install deps
run: npm ci
- name: Fetch articles JSON
run: npx tsx scripts/fetch-all-articles.ts
- name: Fetch OGP with bounded concurrency
run: npx tsx scripts/fetch-ogp.ts
- name: Commit changes
run: |
git config user.name "gh-actions"
git config user.email "actions@users.noreply.github.com"
git add data/*.json
git commit -m "chore(data): refresh articles and OGP" || echo "No changes"
git pushIf you deploy with Cloudflare Pages or Workers from your repo, a push will trigger a redeploy, which publishes the new static JSON globally. The result is a site that updates itself on a schedule without hitting 1102 in production.
Deploying Next.js to Cloudflare the “edge-friendly” way
Use current guidance to target the Workers runtime with OpenNext. This transforms your Next.js build output for Workers, supports the App Router, and lines you up with Cloudflare’s preferred path. If your app is entirely static after the changes above, you can also ship to Pages as a static site.
A minimal wrangler.toml can also specify CPU time caps if you want an explicit safety rail. Cloudflare documents CPU metering and how limits affect pricing and behavior.
How to think about it going forward
We just moved heavy work out of the request path. If dynamic bits remain, we made them cacheable and we limited their fan-out. From here, keep an eye on:
- The number of subrequests per page render. Aim low.
- Whether data can be precomputed at build or on a schedule. If yes, do that.
- Your CPU cap and actual CPU usage for hot endpoints. Tune the cap if you need headroom, but treat it as a guardrail instead of a crutch.
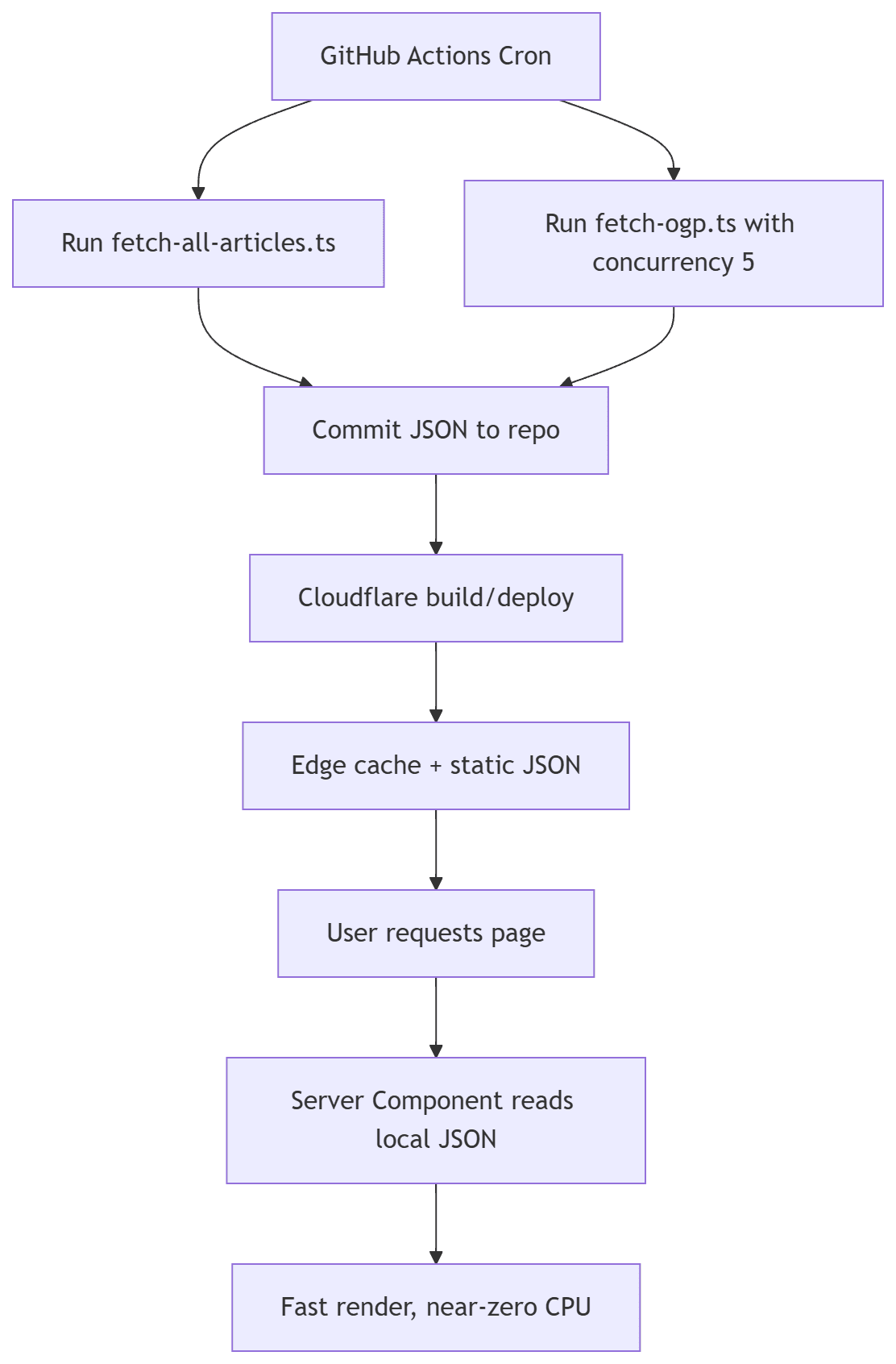
And because pictures help, here is the new flow you’re aiming for:
flowchart TD A[GitHub Actions Cron] --> B[Run fetch-all-articles.ts] A --> C[Run fetch-ogp.ts with concurrency 5] B --> D[Commit JSON to repo] C --> D D --> E[Cloudflare build/deploy] E --> F[Edge cache + static JSON] F --> G[User requests page] G --> H[Server Component reads local JSON] H --> I[Fast render, near-zero CPU]
Troubleshooting checklist
- Still seeing 1102 after these changes? Verify the page is not making internal fetches on the server at runtime. In the App Router, ensure components reading JSON are server components without
fetch()calls. - Inspect the Network tab for a cascade of API calls coming from server transitions or nested Server Actions.
- Re-check your Worker’s configured CPU limit and whether you’re unintentionally running with a conservative cap due to legacy migration.
- Audit subrequests per page render. If you are close to the cap, batch or precompute.







