


Search APIs have historically been built for human eyeballs rather than AI systems. They returned pages, not the specific snippets your model needs; they were slow when scraped from third-party engines; and they went stale quickly. Perplexity claims to have rebuilt the stack for AI: a large, frequently refreshed index, hybrid lexical-semantic retrieval, and sub-document results designed to drop straight into model context. The public launch on Sep 25, 2025 exposes the same infrastructure that powers Perplexity’s answer engine, along with an SDK and an open evaluation framework, search_evals.
Perplexity positions the API as fast and fresh at internet scale: hundreds of billions of pages tracked, tens of thousands of CPUs in play, hot storage in the hundreds of petabytes, and continuous index updates. They report median p50 latency near 358 ms from AWS us-east-1, with quality wins on SimpleQA, FRAMES, BrowseComp, and HLE benchmarks in their research write-up. Treat these as vendor claims, but they are specific and reproducible via their OSS harness.
What you get, concretely
At its core there is a single endpoint:
POST https://api.perplexity.ai/search
Authorization: Bearer <token>
Content-Type: application/json
{
"query": "latest AI developments 2025",
"max_results": 10,
"max_tokens_per_page": 1024,
"country": "US"
}The response returns ranked results with title, url, snippet, and date fields. The SDK mirrors the same contract. Multi-query is supported by sending query as an array, which returns per-query result sets.
The mental model
Think of the Search API as a retrieval primitive to feed your downstream model. You control:
- Breadth with
max_resultsper query. - Depth of extraction per result with
max_tokens_per_page. - Scope with geographic filter
country, domain filters, and “web” vs “academic” search modes in guides.
Below is a simple diagram of how a single query flows through Perplexity’s described pipeline and into your app.
sequenceDiagram
actor Dev as Your App
participant API as Perplexity Search API
participant IR as Hybrid Retrieval
participant Rank as Multi-stage Rerankers
participant Index as Fresh Index (sub-doc units)
Dev->>API: POST /search {query, filters}
API->>IR: Lexical + Semantic retrieval
IR->>Index: Fetch doc + sub-document candidates
Index-->>IR: Candidates with snippets
IR->>Rank: Fast scorers → cross-encoders
Rank-->>API: Top-k results with snippets, dates
API-->>Dev: JSON results (ranked)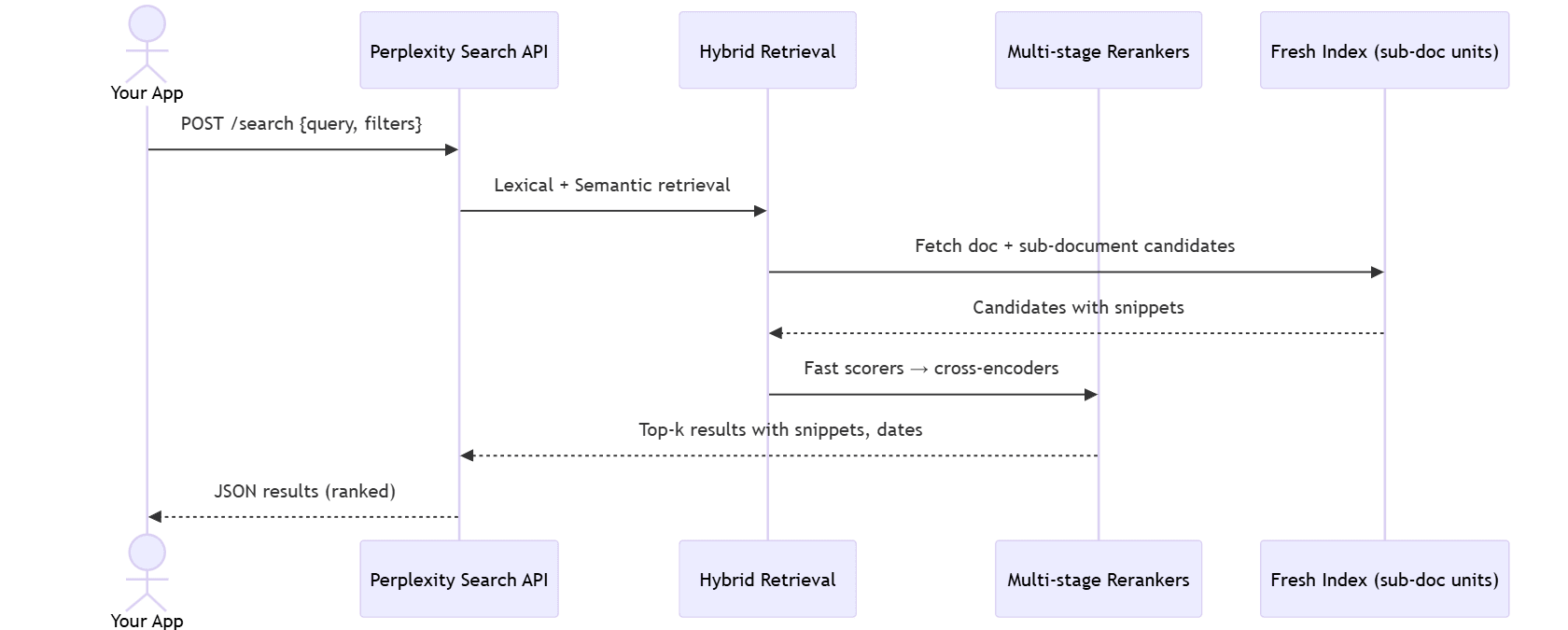
Perplexity’s research article details the hybrid retrieval and multi-stage ranking used to produce those results.
Quick start in practice
Python
from perplexity import Perplexity
client = Perplexity() # uses PERPLEXITY_API_KEY
search = client.search.create(
query="how to deploy Flarum site:dropletdrift.com",
max_results=8,
max_tokens_per_page=1024
)
for r in search.results:
print(r.date, r.title, r.url)TypeScript (Node)
import { Perplexity } from "perplexityai";
const client = new Perplexity({ apiKey: process.env.PERPLEXITY_API_KEY! });
const res = await client.search.create({
query: "why DNS propogation takes so long site:dropletdrift.com",
max_results: 6,
max_tokens_per_page: 1024,
});
res.results.forEach(r => console.log(r.date, r.title, r.url));Both mirror the REST example and parameters in the docs.
Patterns that actually work
1) Answer grounding for chat
Use search to fetch 3–6 high-quality snippets and frame them into a concise, source-attributed context for your model. Keep the context compact; models degrade with bloated input. Perplexity surfaces sub-document snippets exactly to reduce context bloat.
from perplexity import Perplexity
from textwrap import shorten
client = Perplexity()
q = "EU Chat Control, implications 2025"
search = client.search.create(
query=q,
max_results=6,
max_tokens_per_page=800
)
context = "\n".join(
f"- [{r.title}]({r.url}) — {shorten(r.snippet, width=260)}"
for r in search.results
)
prompt = f"""Question: {q}
Use only the sources below. Cite inline as [n].
Sources:
{context}
"""
print(prompt)The goal is minimal, current, and attributable grounding.
2) Multi-query “deepening” for agents
Break a broad task into parallel, specific queries. The guides support up to five queries per request and show async patterns and rate-limit handling.
import asyncio
from perplexity import AsyncPerplexity
queries = [
"developer salaries site:news.ycombinator.com",
"css tutorials site:dropletdrift.com",
"privacy-friendly analytics site:github.com"
]
async def main():
async with AsyncPerplexity() as client:
tasks = [client.search.create(query=q, max_results=5) for q in queries]
results = await asyncio.gather(*tasks)
for i, res in enumerate(results):
print(f"Q{i+1}:")
for r in res.results: print(" ", r.title, r.url)
asyncio.run(main())3) Academic mode for literature scans
Use academic mode and domain filters to reduce noise when you need papers and official guidance.
from perplexity import Perplexity
client = Perplexity()
s = client.search.create(
query="SGLT2 inhibitors heart failure 2024 randomized trial",
# shown in guides; see docs for exact names/values
search_mode="academic",
search_domain_filter=["nejm.org","thelancet.com","ahajournals.org"],
max_results=10
)The best-practices guide shows mode and filtering patterns.
Choosing parameters with intent
- max_results. Request only what you will use. More results increase latency and cost. Perplexity defaults to 10 and caps at 20.
- max_tokens_per_page. This controls how much text gets extracted per URL. Use 512–1024 for general Q&A and 1500–2048 when you plan to chunk downstream. The guide shows trade-offs explicitly.
- Filters. Prefer allow-lists of authoritative domains and a recency filter when currency matters. The guide shows domain filtering and recency patterns.
- Regionalization. Use
countryto bias results to an ISO 3166-1 code when laws, prices, or news differ by region.
Operational concerns that will save you later
- Rate limits and retries. Implement exponential backoff with jitter and batch concurrency. The docs provide Python and TS examples with
AsyncPerplexity. - Caching. Cache successful searches keyed by normalized query plus filters. Respect freshness; when you need today’s data, prefer short TTLs and set a recency filter at query time.
- Deduplication. Many news topics syndicate across domains. Deduplicate by canonical URL and by title similarity before constructing model context.
- Attribution. Keep 3–6 sources. Shorten snippets and force the model to cite as
[1],[2], etc. This improves user trust and guards against hallucinations. - Crawler stance for your own properties. If you operate sites and want Perplexity to surface them, allow PerplexityBot in
robots.txtand, if needed, whitelist IPs in your WAF. The crawler page lists user-agents and published IP ranges.
Quality, latency, and cost: how to think about it
Perplexity’s research article reports p50 latency near 358 ms and leads on quality across SimpleQA, FRAMES, BrowseComp, and HLE, evaluated via their open search_evals framework. Treat this as a starting point, and run your own evals on your domain.
If you are comparing alternatives, look at index freshness, sub-document support, latency under load, and data rights. Brave Search API publishes transparent pricing tiers with high request ceilings; SERP-based approaches vary and often trade latency for coverage. Benchmarks and pricing posts from Brave’s own docs provide useful context while you run your bake-off.
Running your own evaluation
Use search_evals
search_evals provides agent harnesses and plugs in multiple search APIs. Clone it, add your tasks, and run head-to-head tests that reflect your product, not just public benchmarks.
git clone https://github.com/perplexityai/search_evals.git
cd search_evals
# set your API keys as env vars per README
# run built-in suites or point to your JSONL tasks
python -m search_evals.run --suite simpleqa --provider perplexity
python -m search_evals.run --suite simpleqa --provider brave
python -m search_evals.compare --suite simpleqa --providers perplexity braveDefine a few dozen representative questions, including cases where timeliness matters, where you need sub-page citations, and where domain filters are essential. Measure task success, time to first useful snippet, and end-to-end latency for your full pipeline, not just the search call.
Security, privacy, and compliance notes
- Keys and groups. Manage API keys and billing groups in the portal; rotate keys and scope usage by environment.
- Data handling. Use allow-lists for domains when your policy requires vetted sources. Keep logs of URLs used to answer regulated queries.
- Robots and IPs. If you host content, consult Perplexity Crawlers for user-agents and IP JSON endpoints to control access.
Troubleshooting playbook
- Results feel stale. Add a recency constraint, lower cache TTL, and raise
max_tokens_per_pageslightly to capture updated snippets. - Too much noise. Switch to academic mode or apply domain filters. Tune
max_resultsdown to 5–8. - Rate limits. Use the async client with batching and backoff. Log retry counts and successes.
- Latency spikes. Reduce
max_results, lowermax_tokens_per_page, and collapse near-duplicate queries into a single multi-query call.
End-to-end example: building a grounded answerer
import asyncio
import re
from textwrap import shorten
from perplexity import AsyncPerplexity
CITATION_RE = re.compile(r"\[(\d+)\]")
def build_sources(results):
# keep top 5 authoritative sources, dedupe by domain
seen = set()
out = []
for r in results:
dom = r.url.split("/")[2]
if dom in seen: continue
seen.add(dom)
out.append(r)
if len(out) == 5: break
return out
async def grounded_answer(question: str):
async with AsyncPerplexity() as client:
search = await client.search.create(
query=question,
max_results=12,
max_tokens_per_page=900
)
sources = build_sources(search.results)
context = "\n".join(
f"[{i+1}] {s.title} {s.url}\n{shorten(s.snippet, 260)}"
for i, s in enumerate(sources)
)
# hand off to your model here; we just return a template
return f"""Q: {question}
Use only the sources below. Cite as [n].
Sources:
{context}
Answer:"""
print(asyncio.run(grounded_answer(
"EU Chat Control implications for global privacy 2025"))))This shows search assembly, simple dedupe, and a clean prompt for your completion model.
When to reach for this API
Use it when your agent needs current, attributable facts, when it benefits from granular snippets over whole pages, and when latency matters in user flows. Pair it with your existing LLM stack for grounded generation, or as the retrieval layer for internal tools. If you need a comparative baseline, run your search_evals suite across Perplexity and an alternative like Brave, then choose based on your task-level success, latency, and total cost in your environment.







